This update includes possible breaking changes and may require manual steps before/after upgrade. Please carefully review all items tagged with #manual step prior to updating!
Notes
- Empty release for testing In-App Updates 21.1.302
Schema Changes
-
An
IS_INTERRUPTIBLEcolumn has been added to theSCH_ACTIVITY_TYPEandSCH_ACTIVITY_TYPE_Htables. 21.1.321 #347413 -
Several tables beginning with the name
COSTWELLorCOSTWELLCAThave been added to support the Rystad integration. 21.1.319 #358130 -
The
ACCOUNTSandACCOUNTS_Htables have a newCOSTWELLCATfield to allow mapping accounts to Cost Well Categories. 21.1.319 #358130 -
A
COSTWELLfield has been added to theAFEand theAFE_Htables. This field is inactive by default. 21.1.319 #358130 -
A
COSTWELLfield has been added to thePROJECTand thePROJECT_Htables. This field is inactive by default. 21.1.319 #358130 -
We’ve added new fields (
EB_PERMITTEDandEB_NONOP_EMAIL) to thePARTNERSfor future use by Quorum Electronic Balloting. In the interim, you are welcome to activate these fields and use them to track partner electronic balloting consent and contact addresses. 21.1.295 #334262 -
We’ve added new tables
AFE_APPROVAL_PATHandAFE_REVIEW_PATH(and accompanying*_DOC,*_DOC_V,*_Htables) to support the new AFE path workflow functionality. 21.1.295 #334867 -
We’ve added new fields to the
AFE_PARTNERtable to track future Electronic Balloting status. These new fields are:EMAIL,EB_ID,EB_RESPONSE,EB_RESPONSE_DATE,EB_SENT_DATE,EB_COMMENT, andEB_VIEWED_DATE. All fields are inactive by default. 21.1.295 #334262 -
We’ve made changes to the structure and data of our behind-the-scenes AFE partner status table
STATUS_AFE_PARTNER. These changes will pave the way for us to introduce additional partner statuses in the future. For example: “Consent (limit participation to my WI)” and “Consent (and will carry proportionate share)”. 21.1.295 #334262 -
New
APPROVAL_PATHandREVIEW_PATHfields were added to theAFEto support the new Approval/Review functionality. These fields are inactive by default. 21.1.295 #334867 - Added PARTNER.LOGO_BASE64 and USER.SIGNATURE_BASE64 fields to store images for forms use. 21.1.291
-
Added new
CHUNKcolumn toEXECUTE_DOCUMENTSin Warehouse schema. A document may now be split across multiple chunks (having multiple rows). 21.1.277 -
Removed the data column from
EXECUTE_DOCUMENTS_LATESTin SQL Warehouse schema. 21.1.277
Features️
-
An administrator can mark documents as Global Templates to provide a starting point to create a new AFE, Job, Well, Site or other document.
#ui
#admin
21.1.325
#361485
To create, edit, or remove Global Templates, you must have the Manage Global Templates privilege. Users with this privilege will see an “All Global Templates” report in the report list on the browse page of eligible documents.
To mark a document as a Global Template, view the document and select “More > Mark as Global Template”. A Global Template Description is required and can guide creators as to the information within that template. Documents that are marked as a Global Template can only be edited by users with the Manage Global Templates privilege. Once a document is marked as a Global Template, creators will see a list of the templates under the “Create New” button.
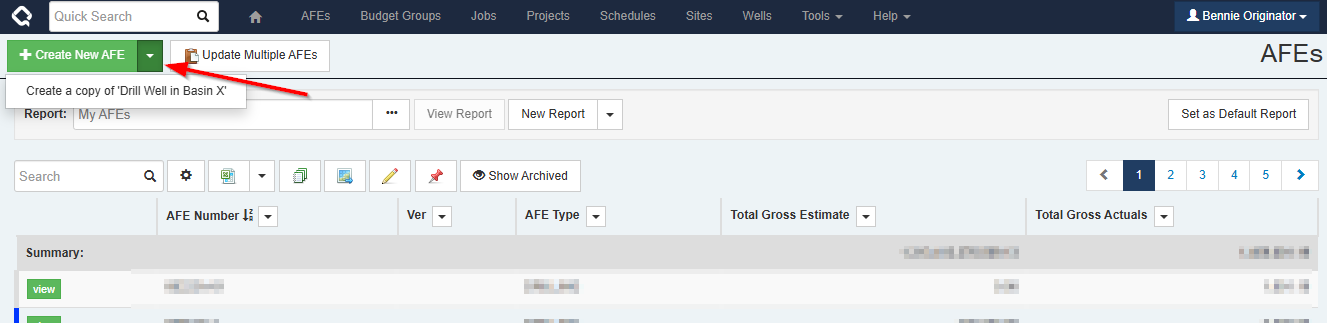
If a creator has used the template button on an AFE or a Job to create their own templates, these user templates will also be listed under the “Create New” button, along with any Global Templates.
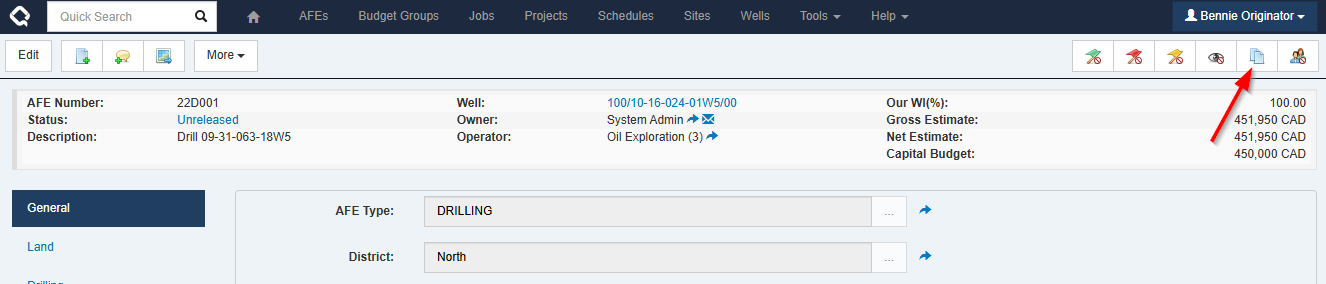
There are two columns that can been added to a browse report in order to find documents that have been marked as a Global Template:
- Is Global Template
- Global Template Description
A creator will only see Global Templates listed that they have permissions to see, according to their view rights.
Note: If your organization uses advanced workflows and plans to use the Global Templates feature, you may want to adjust the workflow activation rules to exclude documents marked as a Global Template.
-
Introducing the Bulk Sync API to streamline your data synchronization process. The functionality of the Document Synchronization plugin is now available as an API endpoint with a straightforward CSV data format.
#api
#system
21.1.323
#351573
Bulk Sync API
A new API (
POSTto/api/bulk/sync) allows bulk creation, updating, and inactivation of documents using CSV data.This can be used to keep a list of data in Execute synchronized with an external system. Any tool that can extract data as a CSV file and perform an HTTP POST will now be able to update Execute data.
Example Usage
The API is reached at
https://YOUR_SERVER/api/bulk/sync?type=PARTNER&dryrun=true.Authentication uses Execute API Keys via HTTP Basic Auth.
The
type=query parameter is required and indicates which Execute document type will be updated.Other parameters are available to control the sync behaviour, see the documentation.
The
dryrun=trueparameter is useful for testing — it runs the full sync and returns a report of what would happen without making any changes to the data. Remove it (or set it tofalse) when ready to commit.Each row in the CSV identifies one or more documents and provides value columns to update the data on the matched document(s).
The CSV header row contains the field path for each column. Columns prefixed with
$are key columns used to find matching documents; the remaining columns are the values to update.Here is a CSV for Execute PARTNER data which will match on the partner code to update the name and address.
COMNAME,$CODE,STRADDRESS Sesame Exploration,39,123 Sesame Street Micro Eggbert Oil,12,"1111, 111 - 1st Avenue S.W." Example Ltd.,10,"3300, 333.3 - 3rd Avenue S.W."It could be sent to the Execute API with
curllike so:curl -u "$APIKEY_ID:$APIKEY_KEY" \ -X POST "https://YOUR_SERVER/api/bulk/sync?type=PARTNER&dryrun=true" \ -H "Content-Type: text/csv" \ --data-binary @sample.csvWith
dryrun=true, the response shows what would happen without making any changes:Record,Level,Message 1,Info,DRY RUN: Would update document a1b2c3d4-... 2,Info,DRY RUN: Would update document b2c3d4e5-... 3,Info,DRY RUN: Would update document c3d4e5f6-... Summary,Info,"Summary: 0 created, 3 updated, 0 unchanged, 0 inactivated, 0 errors, 0 warnings"Once the results look correct, remove
dryrun=trueto commit the changes. The response will then confirm what was actually updated:Record,Level,Message 1,Info,Updated document a1b2c3d4-... 2,Info,Updated document b2c3d4e5-... 3,Info,Updated document c3d4e5f6-... Summary,Info,"Summary: 0 created, 3 updated, 0 unchanged, 0 inactivated, 0 errors, 0 warnings" -
Schedule activities can now automatically extend their duration when a resource is unavailable. This can be used to implement “5-Day Scheduling” by marking the weekends as unavailable time on a resource. So go ahead - give your crews weekends off!
#opsched
#ui
21.1.321
#347413
Interrupted Schedule Activities
Schedule activities can now be set as interruptible or non-interruptible (
Tools > Configuration > Schedule Activity Types). If an activity is interruptible, the activity’s duration will extend when it overlaps an exclusion period on the primary resource.Please note that the Enersight schedule integration does not yet export the extended duration values for activities which are interrupted. We will change this in an upcoming release.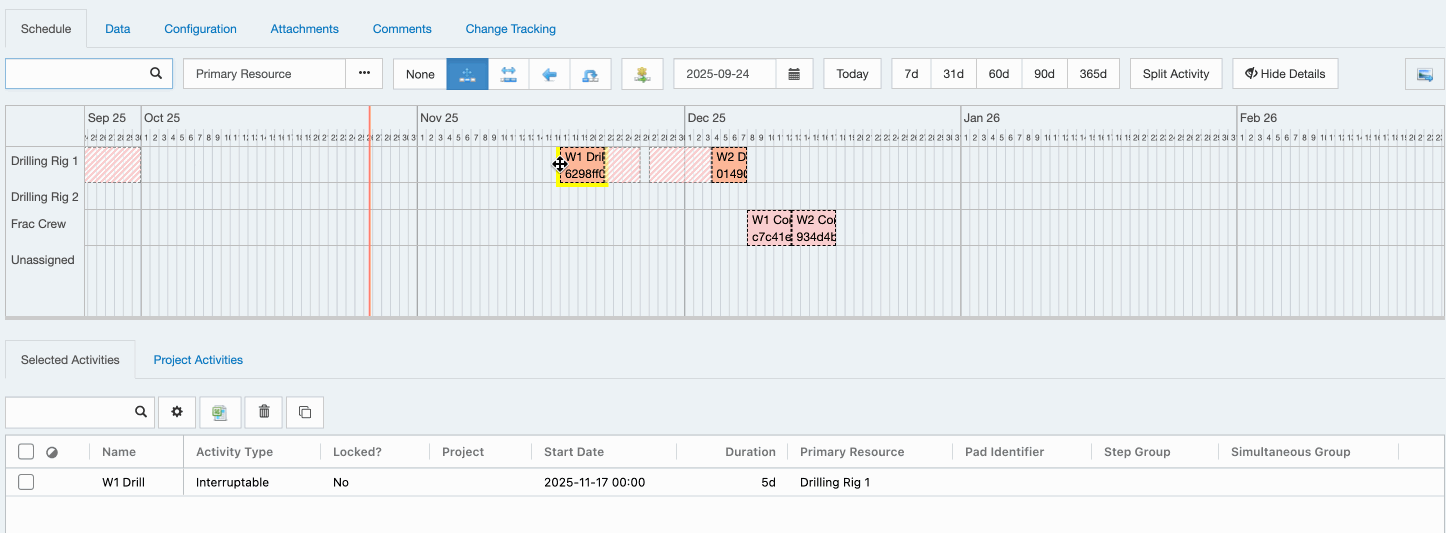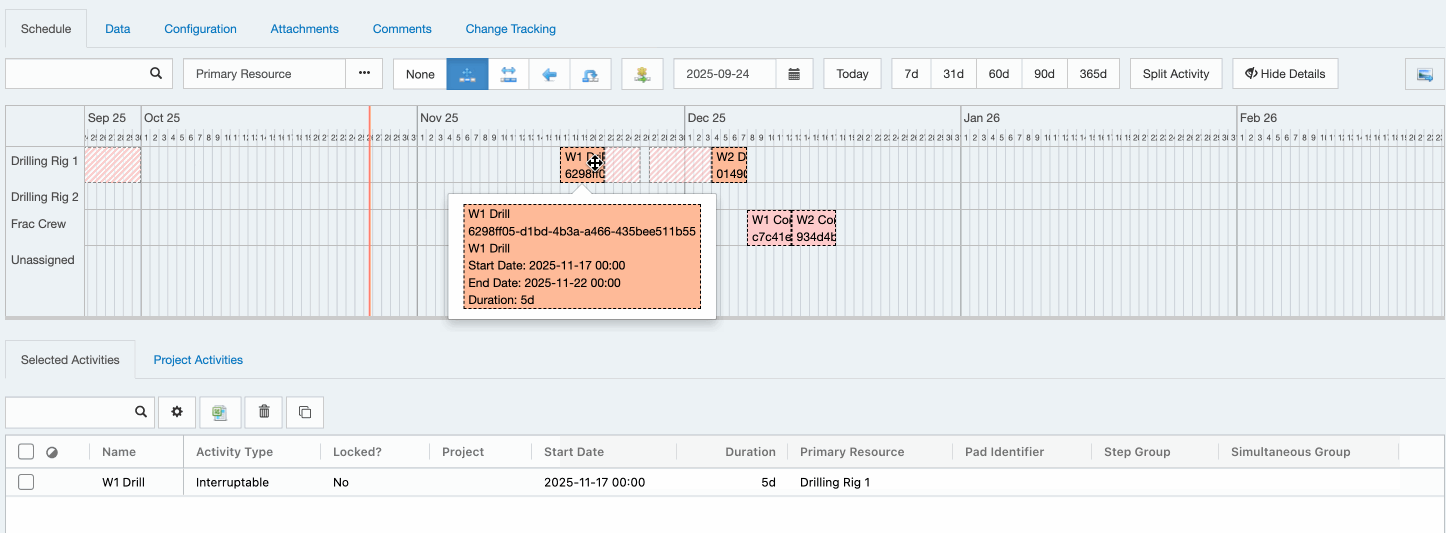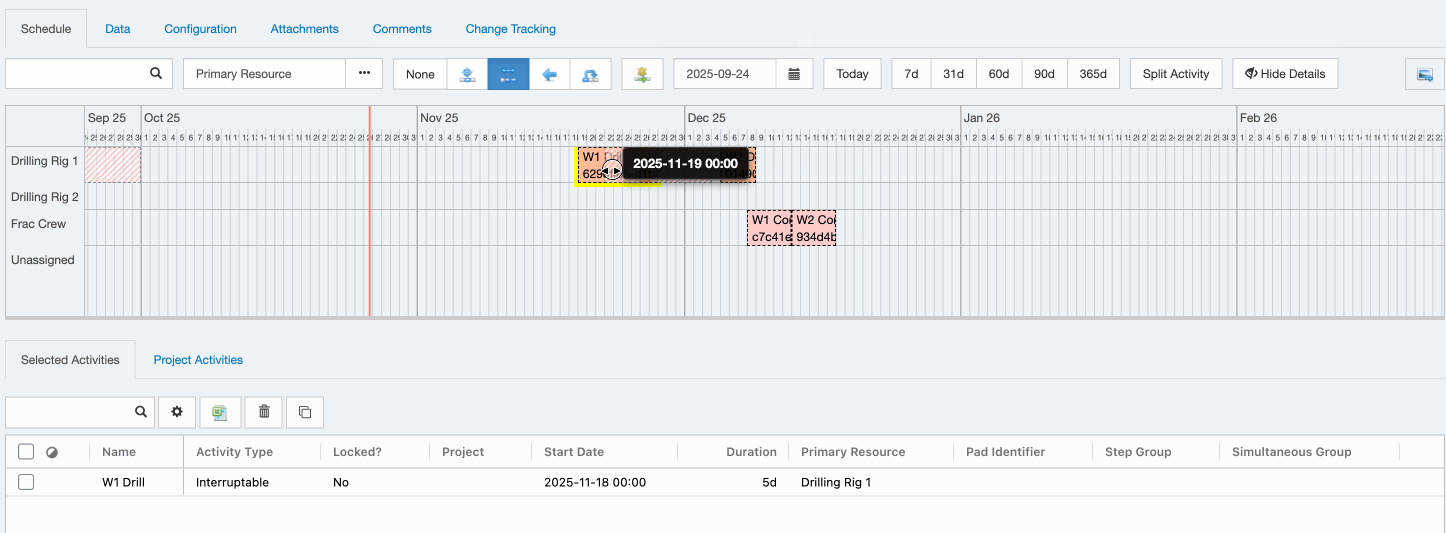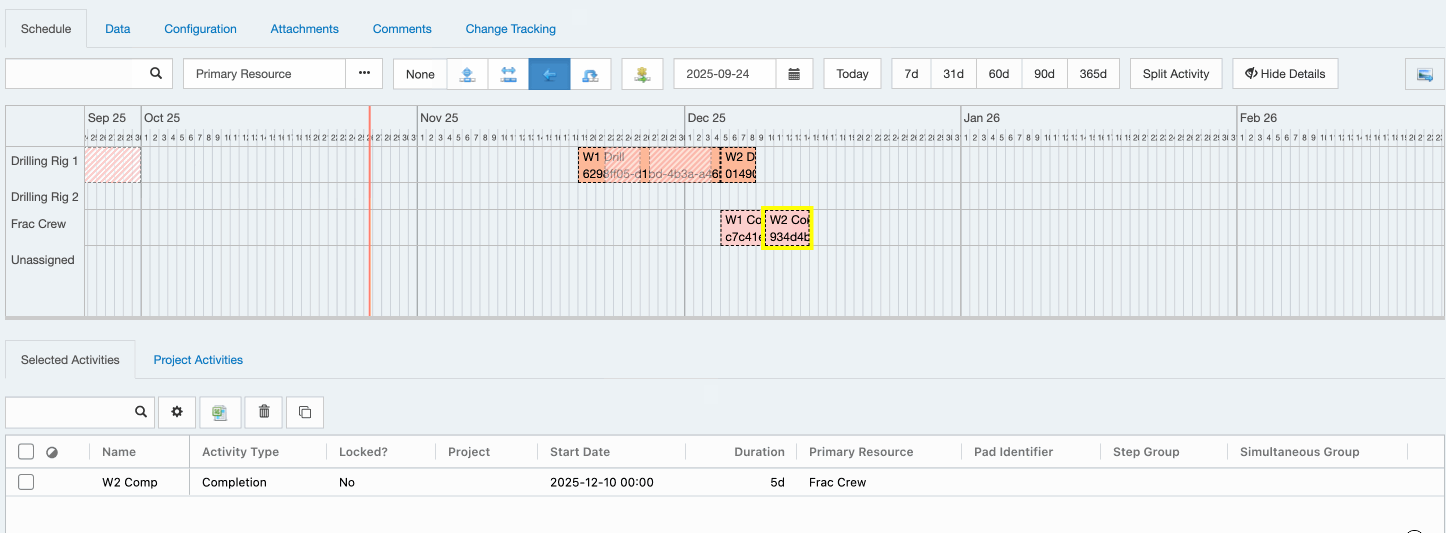
For example: An activity with a 4 day duration is assigned a primary resource that is not available on a weekend.
- If the activity starts on a Monday, the activity runs on Monday, Tuesday, Wednesday, Thursday.
- If the activity starts on a Thursday, the activity runs Thursday, Friday, takes the weekend off, and continues Monday and Tuesday.
The
Durationfield on the activity does not change as it will continue to show the “actual” duration of the work. When viewing the content on the activity, you would see an elapsed duration that includes the time that the resource is unavailable.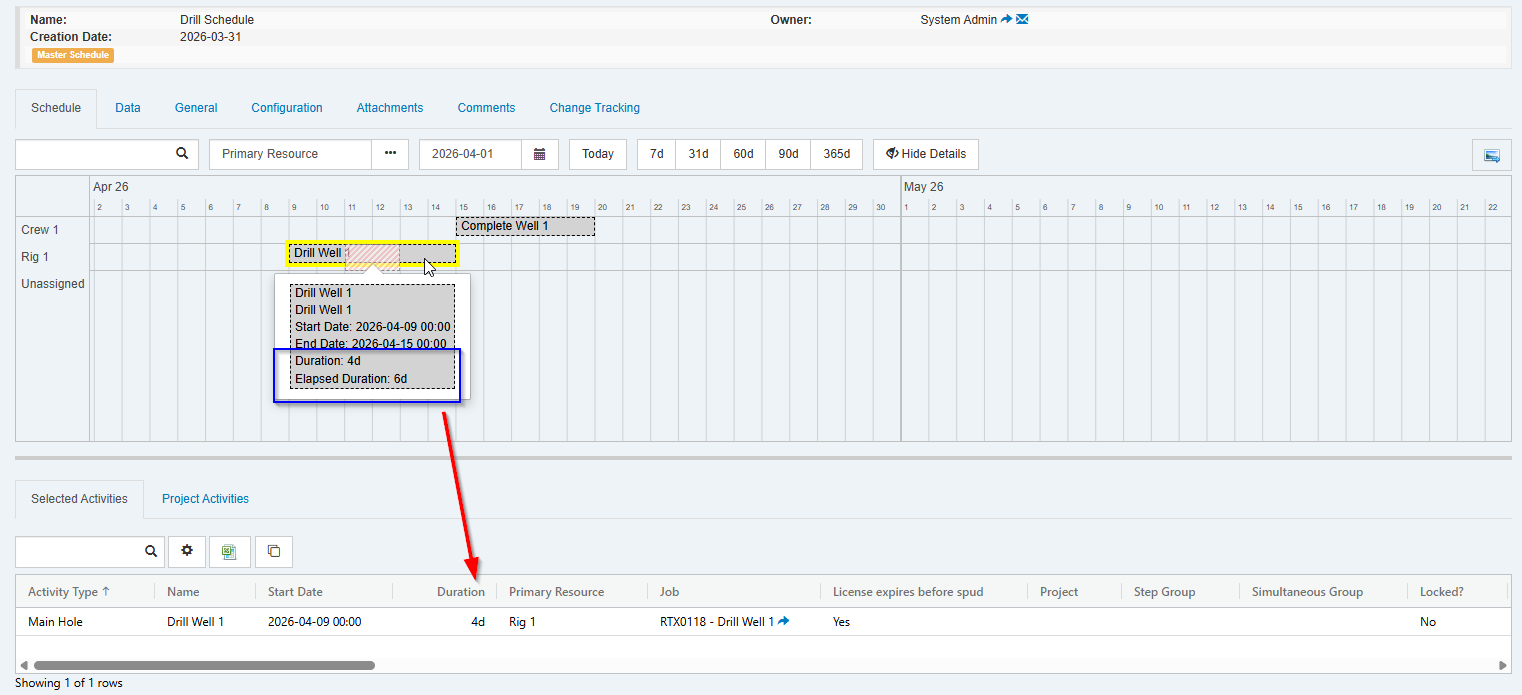
A Job that is linked to an interrupted activity will show the elapsed duration (see example of linked Job below).
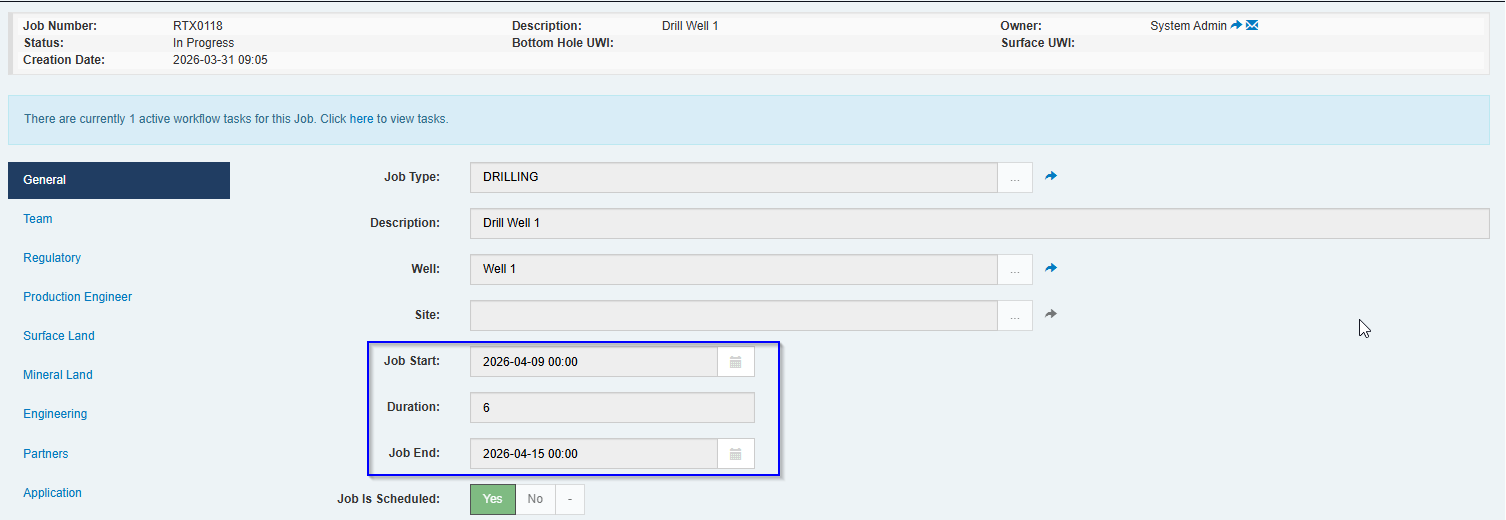
An interrupted schedule activity that is linked to a capital activity on a project will cause the project to appear in the Due for Forecast list, as the timing for the activity has changed.
-
Execute now integrates with Rystad Energy to bring their world-wide, industry data directly into the AFE and Capital Budgeting (Projects) workflow. A “Cost Well” entity has been added to serve as a capital-focused template for a well. AFEs and Projects linked to a Cost Well can display validation messages if the estimates or capital for project activities doesn’t align with the benchmark data in the Cost Well.
#integration
#well
#afe
#budget
21.1.319
#358130
Rystad Integration
The Rystad integration requires a subscription to Rystad Energy but there is no additional licensing required for Execute.
At a high level, the integration allows Execute to:
- Query capital data from Rystad and load that data to a Cost Well entity (or a document if we’re using Execute lingo!)
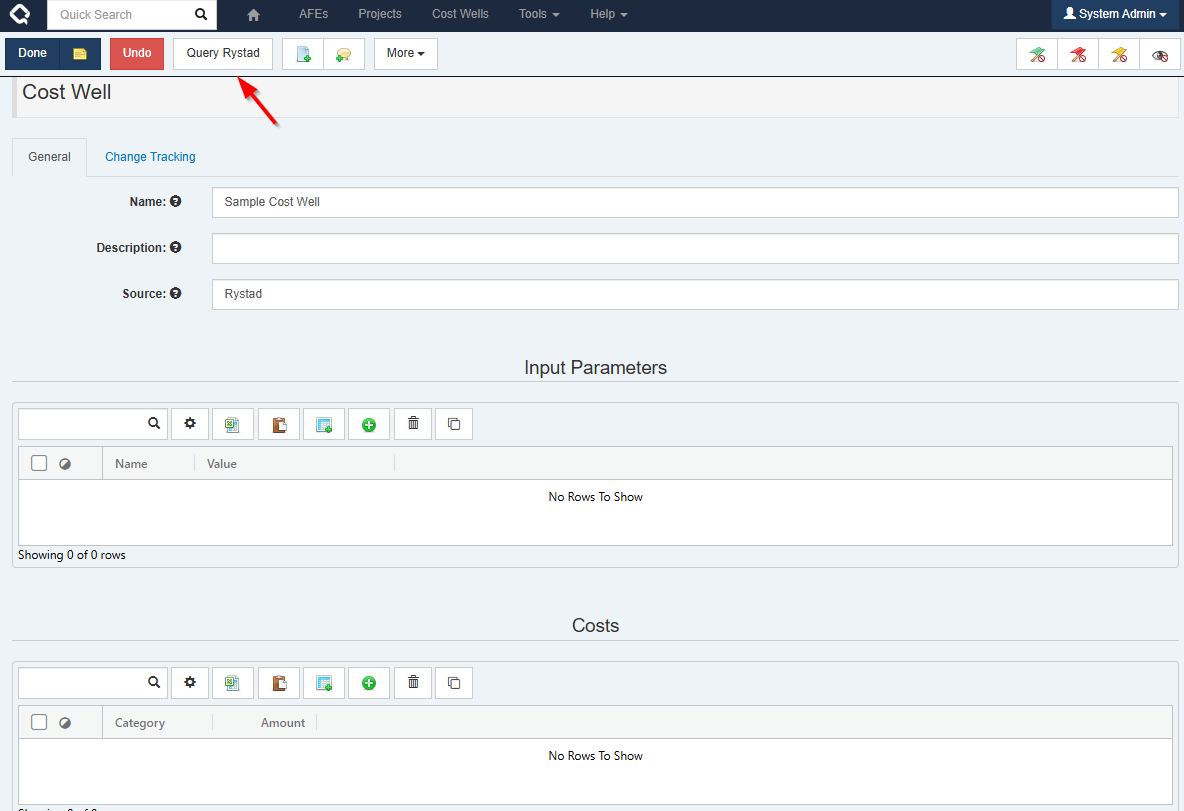
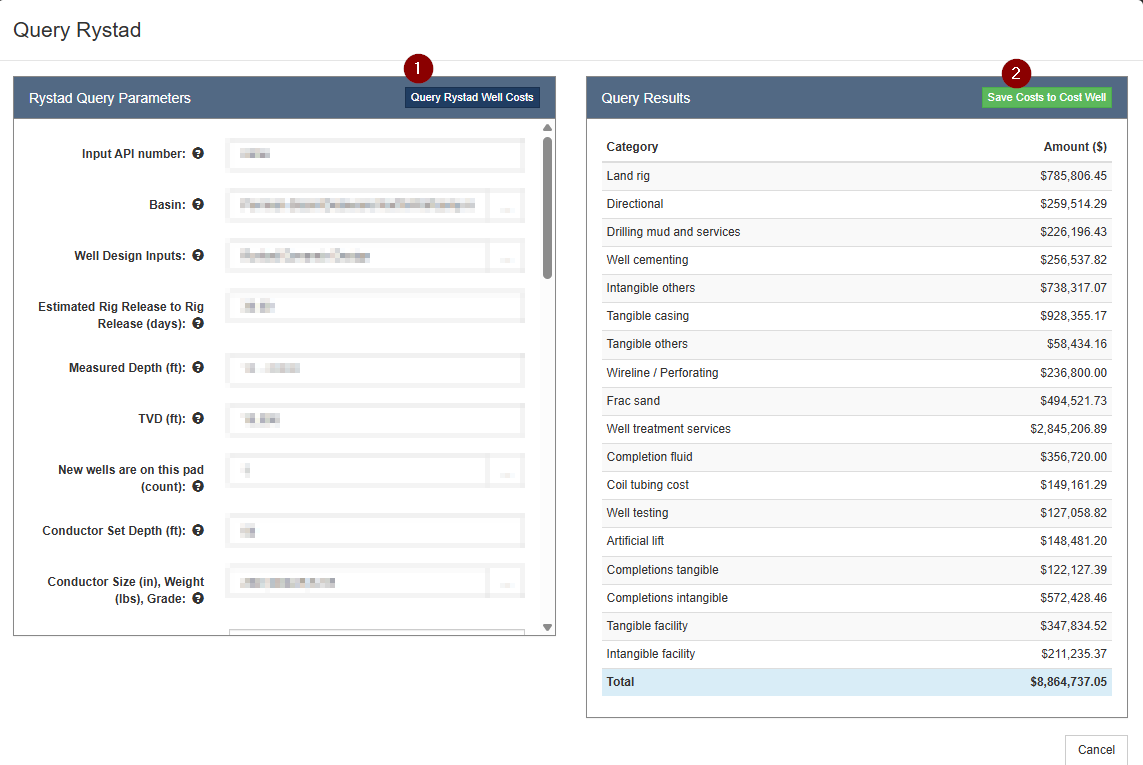
The input parameters used for the query and the resulting costs are written to tables on the Cost Well. The costs are organized in categories that we refer to as Cost Well Categories.
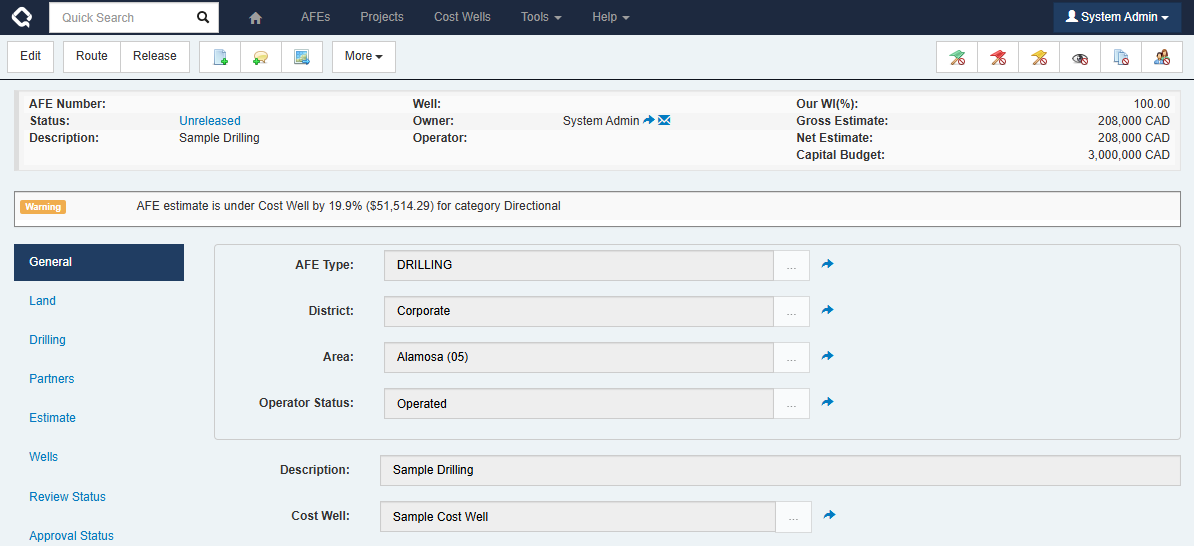
- For an AFE, the GL accounts are mapped to Cost Well Categories. Then, you can link a Cost Well to your AFE and validation messages appear if the AFE’s estimate is under or exceeds the costs in the Cost Well.
- For a Project, Cost Well Categories are mapped to project activity types. By linking a Cost Well to a Project, validation messages are displayed if your costs do not align with the mapped cost well category.
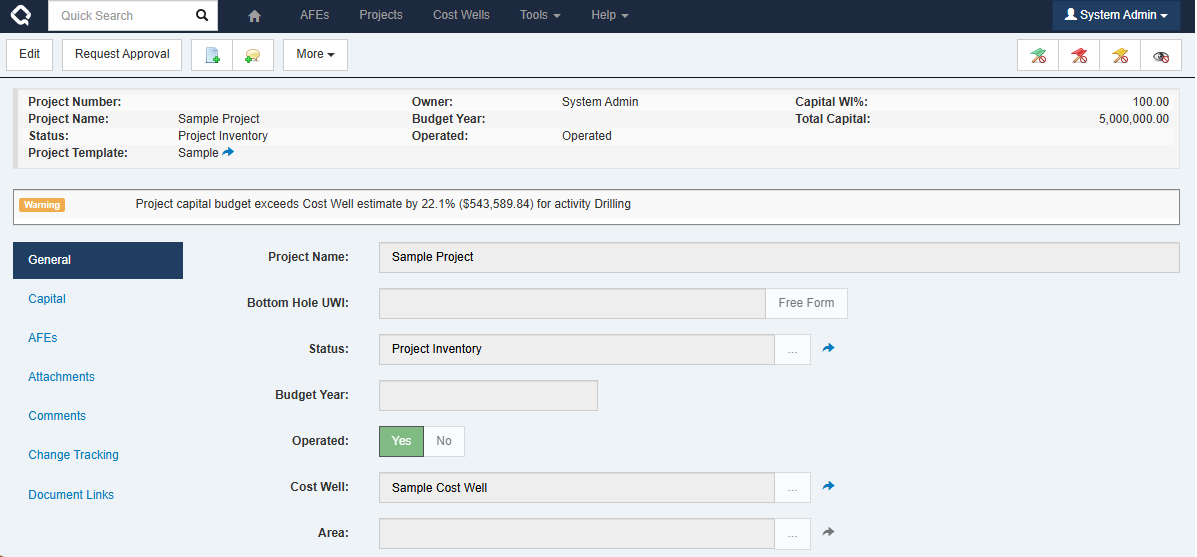
This doesn’t replace the current detailed estimation process that our customers use today. This isn’t authoring the estimate. The goal is context and confidence, not replacing engineering judgment.
- Introducing Databricks Data Selectors & Sync (Beta), a new feature that allows users to easily select and synchronize data with a Databricks environment (via the Databricks API). This is beta functionality and not yet suitable for production use. #integration #workflow #system 21.1.317 #356515
- Execute Electronic Balloting is now Available! Execute Electronic Balloting is a powerful new module that seamlessly extends Execute AFE, transforming the way operators collaborate with partners. With a single Send click, ballots are securely delivered to partners - whether they use Execute or not - eliminating manual email chains and PDF chaos. Track delivery and partner status in real-time. Responses flow directly back into Execute, automatically updating ballot positions and saving hours of administrative effort on every AFE. Faster workflows. Better visibility. Less busywork. #afe #balloting 21.1.316
-
The new Document Links Graph Visualization lets you explore document relationships in an interactive network diagram, making it easier to understand hierarchies and associations at a glance. Colored nodes represent different primary document types, with a clear legend and a gold border highlighting the current document. You can click any node to jump directly to that document, while solid and dashed lines visually distinguish parent-child and association links.
#ui
#system
21.1.306
#346630
This adds a new visualization of how your documents are related to each other on the Document Links tab making it so much easier to navigate between related records.
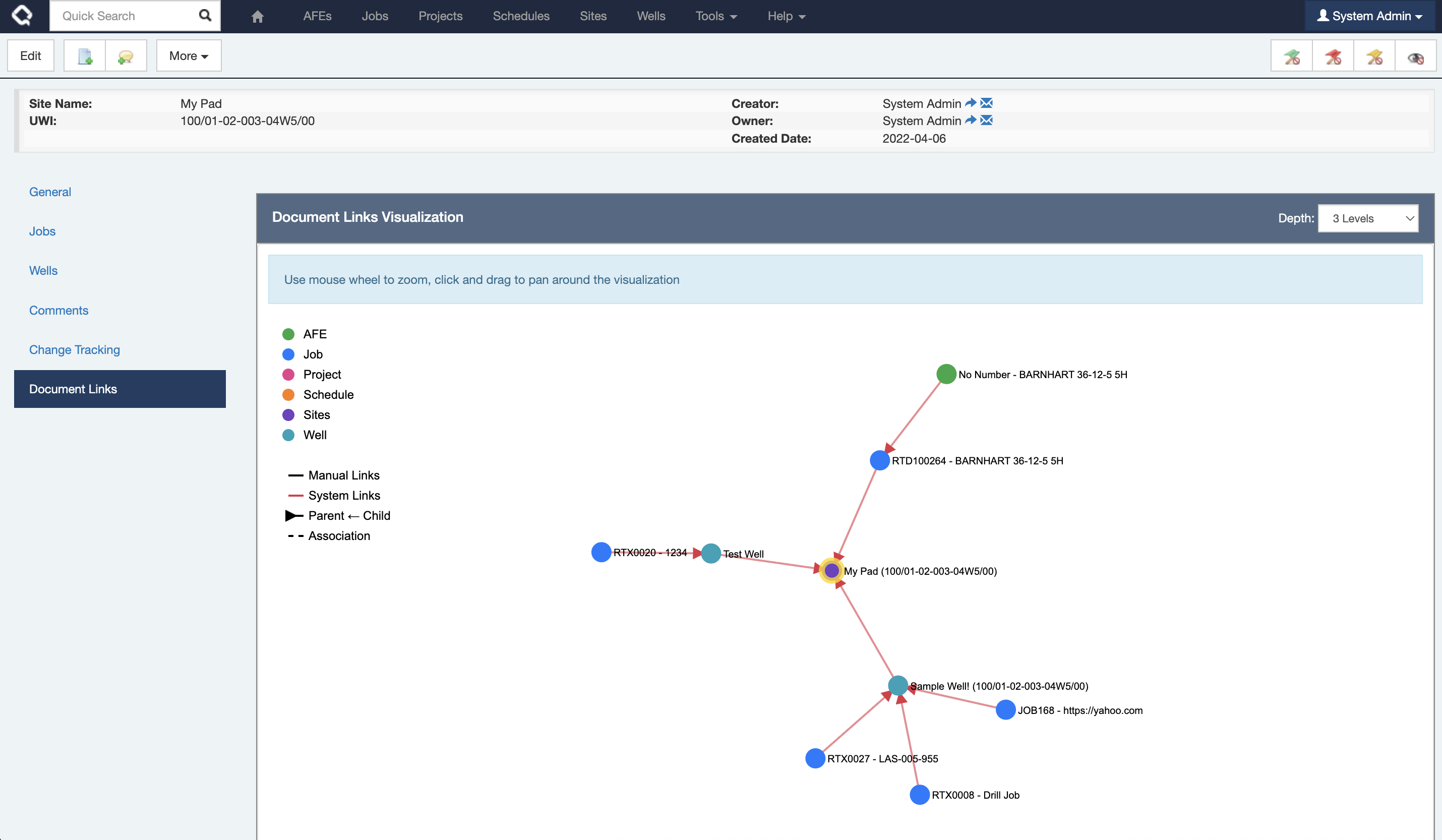
NOTE: If this feature doesn’t make sense in your environment, you can disable it by setting the
HIDE_DOCUMENT_LINK_GRAPHconfiguration flag in settings. -
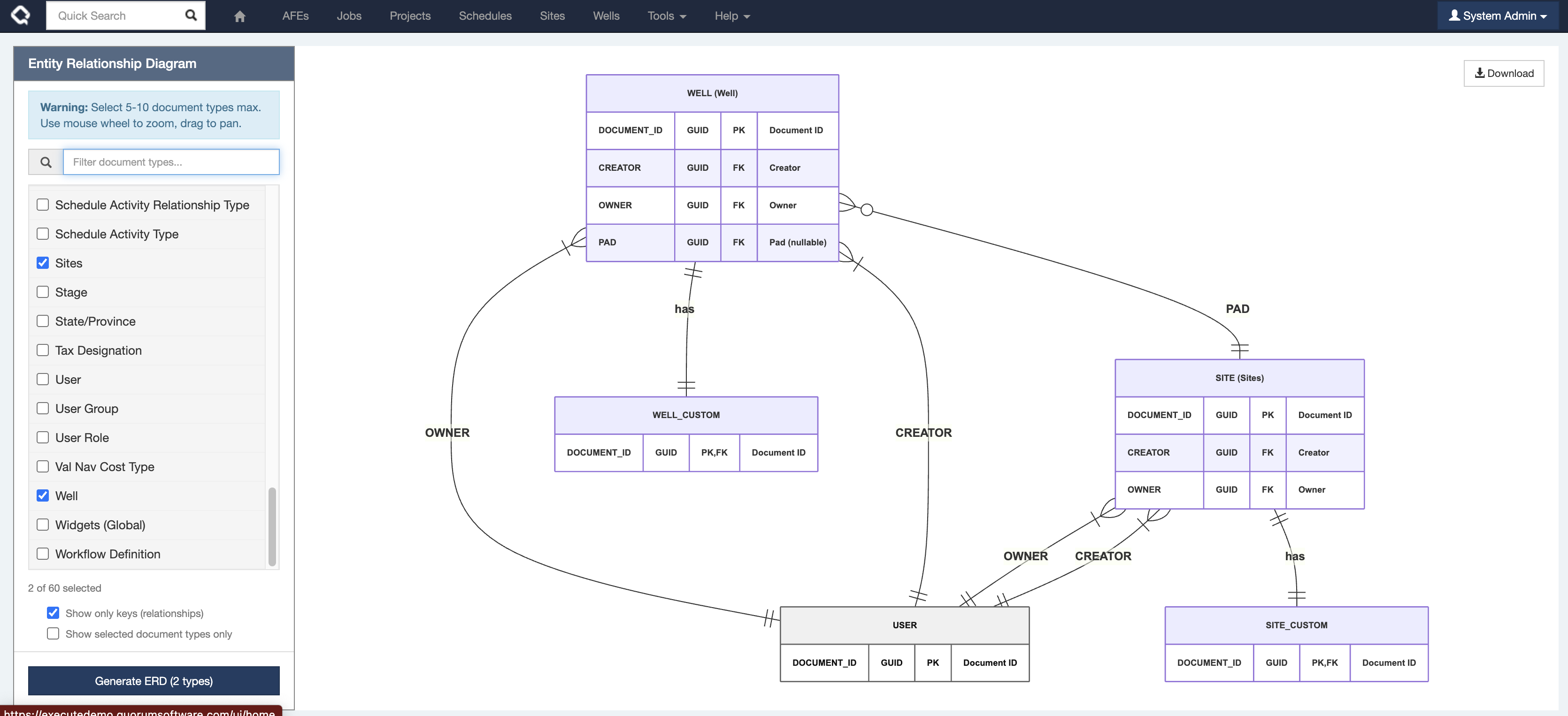
Trying to explain how Execute tables are related? You can now use the ERD diagram generator tool to visually map the relationships between Execute tables in DataHub or your data warehouse. Simply select your Document Types, and the tool will create a clear Entity Relationship Diagram to help you navigate complex schemas with ease. Find on the special page (
/ui/tools?erd) #integration #system 21.1.306 #347425If you have questions about how table are related in our warehouse schema (DataHub, Snowflake, DataBricks, etc.), our new interactive ERD generator will help you make sense of it.
-
Introducing AI-powered formula generation. Note this feature is off by default, and requires an OpenAI / Azure AI API key to enable. If you are interested in testing this feature, please get in touch with Quorum Support.
#formula
21.1.306
#346164
Execute’s new AI Formula assistant makes building, updating and understanding formulas a breeze!
This functionality is available as a preview and not-enabled by default.
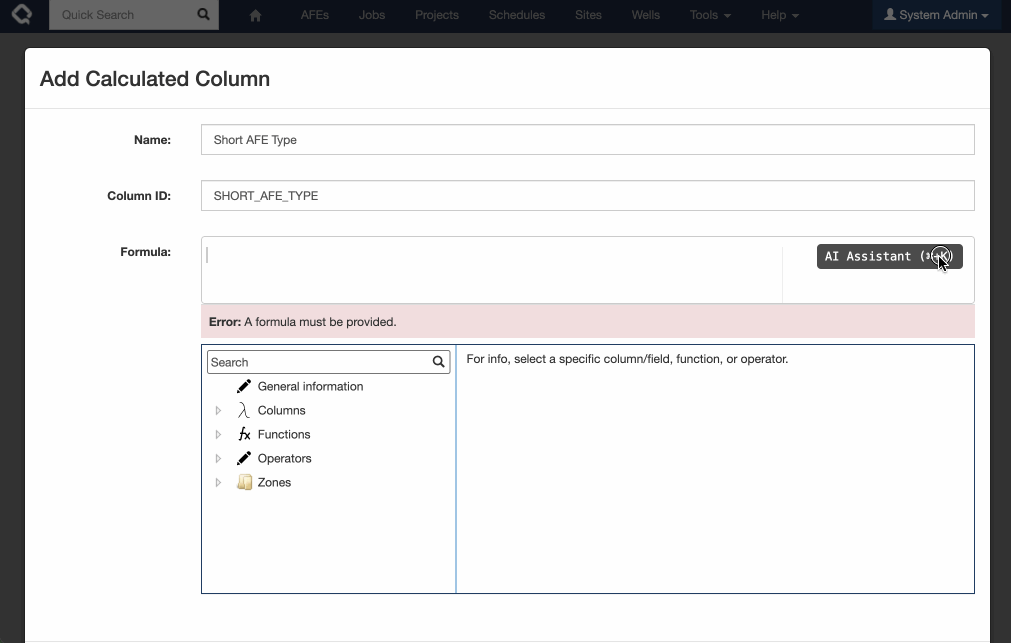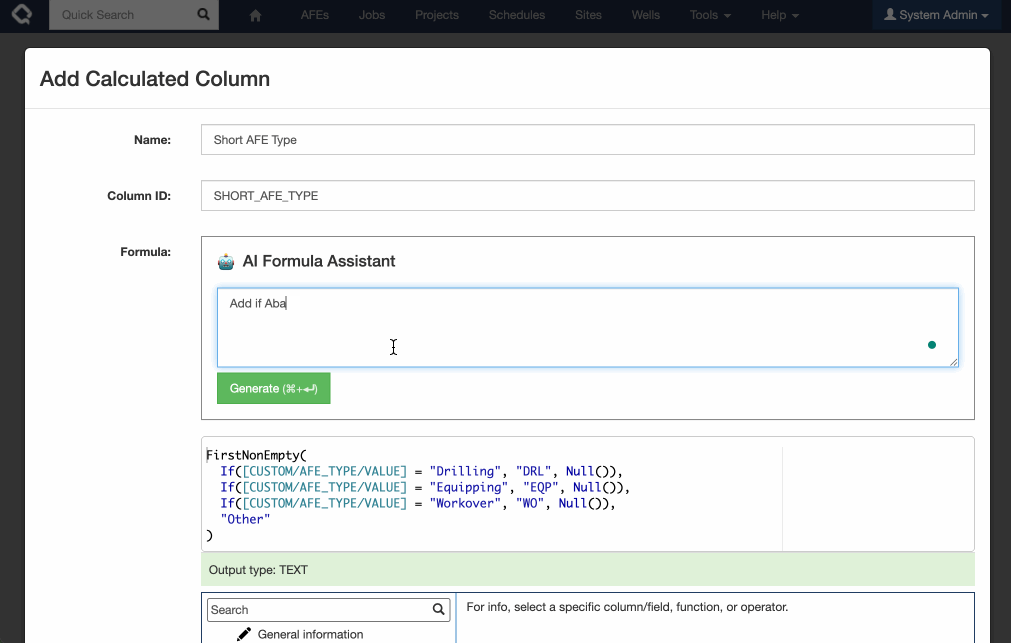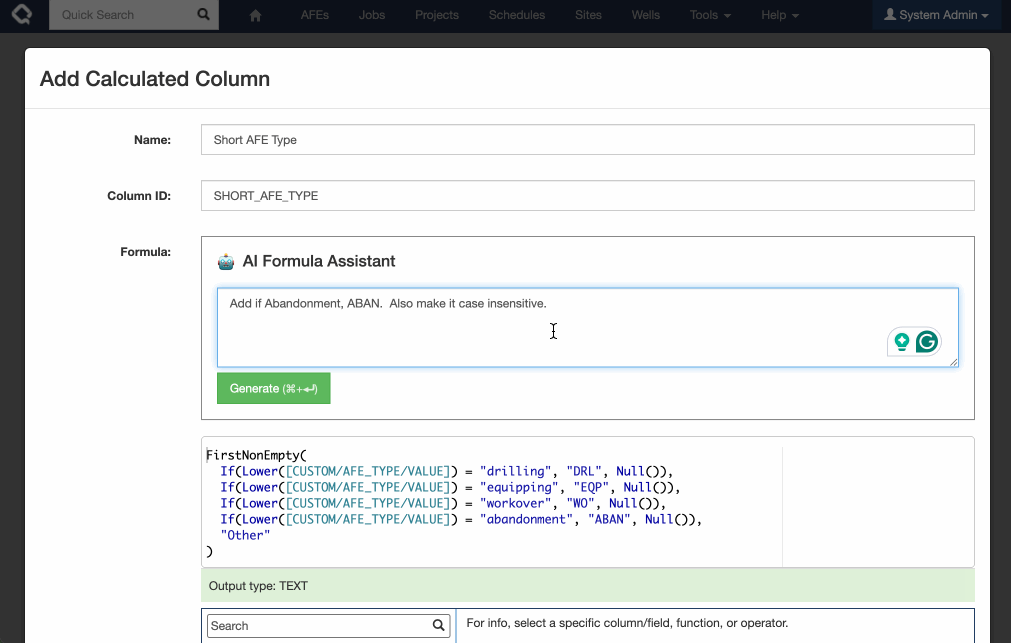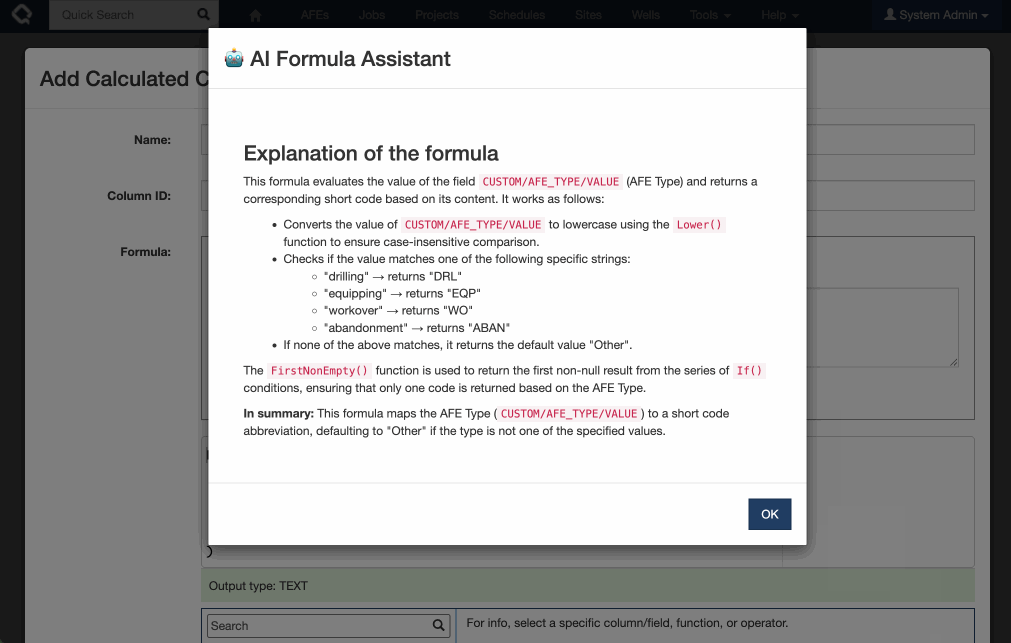
To enable you must:
- Add the
ENABLE_AIconfiguration flag underTools > Configuration > Settings. - Set up your AI provider in the Settings (OpenAI is the easiest and default option, but Azure AI works too)

- Add a new External Credential with your OpenAI / Azure AI API Key. The credential must be called
AI_APIKEY
NOTE: By enabling this experimental feature you understand that some information about your Execute environment is being sent to your configured AI provider including a complete field list, and details about your formulas.
- Add the
- Execute can now be configured to log system messages to Azure AppInsights. This is primarily to streamline monitoring and support of Quorum-hosted Execute environments, but may also be used by on-prem customers if desired. #system 21.1.298 #312727
-
By popular demand… Execute now allows you to automatically release an AFE for approval after review is completed!
#afe
#admin
21.1.298
#341618
Using the new
automatic_release.config.sampleplugin, you can configure Execute to automatically release an AFE for approval when the review process is complete.- Create a new System Review Position Rule called something like “Automatic Release for Approval” (the name doesn’t matter). Record the
DOCUMENT_IDfor this position (the GUID in the URL).- Don’t include any people on this position. The system will automatically mark it as review complete once all other reviewers have finalized their review.
- Adjust the position rule to include it as the last reviewer on any AFEs you’d like the auto-release behavior for. This lets you fine-tune the behavior (maybe you want this on EVERY AFE, or maybe just your Abandonment AFEs).
- Create a plugin from
automatic_release.config.sampleand update thepositionRuleIdto be theDOCUMENT_IDvalue obtained earlier. - Restart Execute
Now… When you save an AFE that is (a) routed (b) has only this single reviewer as incomplete… and it’s the special new “Automatic Release” reviewer, it’ll automatically complete the review and release the AFE for approval.
- Create a new System Review Position Rule called something like “Automatic Release for Approval” (the name doesn’t matter). Record the
- Foundation for Execute’s new in-app update mechanism, which will allow an authorized user to upgrade to future releases from within Execute. Note that this change does make changes to the folder structure of the Execute Service and adjusts permissions for the Execute service user so that it can make future updates to those folders and the Execute Service itself. #admin #system 21.1.298 #316299
-
Most Execute documents now support “Shared Locks”. This means multiple users can simultaneously edit the same document (Well, Job, or Site) and have their changes magically merged together. This helps avoid those situations where you can’t update your job with the latest spud date because Jim was busy updating the job’s safety information and went for lunch leaving it locked.
#system
21.1.298
#327274
Since early times, Execute ensured that only a single user could edit a document (AFE, Well, Job, …) at a time. This was handy for some document types (such as AFEs) with a very strong workflow, but a bit cumbersome for heavily multi-person documents like Wells, Sites and Jobs.
So… we’ve changed things a bit.
Execute will now take shared locks for Wells, Sites, Jobs and all of your custom document types. This allows multiple users to be actively editing the same document and, upon save, their changes will be merged together. It means a whole lot less waiting for someone else to finish their work before you can do yours!
Note: If you are making changes where you think you would benefit from the old-style exclusive locks, you can find “Edit with Exclusive Lock” under the more menu.
This functionality gets really interesting when you include fields from related documents on custom tabs. Previously, for example, you could include read-only well-level fields on your Job for reference but now you can opt-in to allowing those well-level fields to be editable (from the Job) by adding
EDIT_REFERENCED_DOC_FIELDSto your “Additional Configuration Flags” in settings. -
Introduced new Approval/System Review paths, which provide another great option for creating and managing your business rules. Approval/Review paths are intended to be very simple to build and understand. As a bonus, they also better support integration with 3rd-party systems that don’t share Execute’s concept of Approving Position.
#afe
21.1.295
#334867
AFE Approval/Review Paths
This release introduces a new out-of-the-box way to define approval rules in Execute called AFE Approval Paths, and the same for system review called AFE Review Paths.
What are they?
Paths are a new option for modeling approval/review rules in Execute.
This feature introduces two new document types (“AFE Approval Path” and “AFE Review Path”) that can be used to define different paths of individuals an AFE can flow through for approval and review.
For the remainder of this document, we’ll talk about Approval Paths but, for the most part, Review Paths are the same (except they don’t have $ limits).
Here is a sample Approval Path that defines a three-approver approval path for completion AFEs.
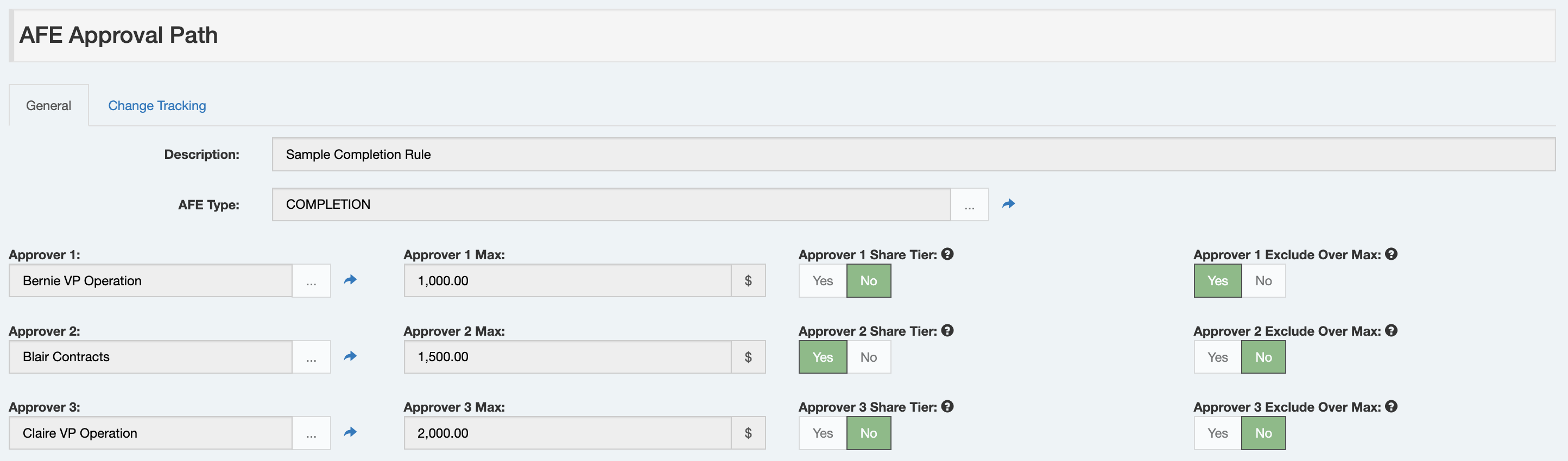
Next, an Approval Path is selected for an AFE (using the AFE’s new
APPROVAL_PATHfield). This selection can be entirely manual (which may be a great low-setup-effort option), “smart-manual” (using list filters to limit selection to valid approval paths that the user can then choose from - i.e. here are the three options for drilling AFEs), or “full-auto” (using a list filter setup to always identify a single Approval Path for each AFE with no user interaction needed).When releasing the AFE for approval, Execute will look at the Approval Path linked to the AFE and add those approvers to the AFE.
A couple of key notes, however…
- Approval Paths specify individuals and not positions. This makes building the rules far easier for those of you who think in these terms. Execute does require positions, however, so we automagically create them as required.
- These are meant to be a simpler option, not a replacement for Blockly. While they have a bunch of great functionality (maximum approval authority, tiers, and exclude-if-over-max), they can’t do everything that the more powerful Blockly rules can.
Why are they?
Our current approval rules are great, but there are a few aspects of them that are problematic for some customers.
- They are complex. Some companies struggle with describing their approval rules as “individual positions with a blockly-based should-I-approve-this-AFE rule”.
- Many companies think of approvals as “Bob is authorized to approve up to $2M”, which is difficult to model in Execute’s Blockly-based rules where, instead, you need to add a rule to the person after Bob that says “Bob’s boss sees everything above $2M”.
- Some companies really struggle to think in terms of approving positions. They think in terms of individual people.
- Some companies have their approval rules defined in another system and want to leverage that. It is very difficult to automate the creation / management of the current Execute approval rules.
So…
Approval Paths give another option which will be easier to work with and maintain for some companies.
As a bonus. Because Approval Paths are simple “Documents” in Execute…
- You can report on them
- You can update them with Browse Edit mode
- You can import them / update them from Excel
- You can load them with Data Loaders
- You can load/update them automatically with Document Sync
- You can easily create/manage them with our APIs
How do I turn them on?
- You should enable the
APPROVAL_PATHfield on the AFE and, somehow, provide a mechanism for it to be set.- (Easiest) Add the field to an AFE custom tab and have someone fill it in. If that’s too open, you can always use list filters to limit which Approval Paths can be picked based on attributes of the AFE (the default is filtering by AFE Type).
- (Harder) Automate the selection. Make the
APPROVAL_PATHeditabilityNever Except Batchand ensure the Blockly List Filters are set up to always identify a single Approval Path for each AFE (Execute will then automagically attach it).
- You need to give your admin user the “Manage AFE Approval Paths” privilege.
- You need to add some Approval Path documents. (NOTE: the default setup filters approval paths by AFE Type, so make sure to create Approval Paths for each AFE Type)
FAQ
What AFE amount does this approve on? Gross? Net?
This feature honors our standard setting “Approval Amount Type” which allows you to select between approving on Gross, Net, or Net on Non-op.
Can I ensure that AFEs have at least one approver with sufficient authority?
You sure can using the new “Require Sufficient Approval Path” setting.
When set, the system will prevent the release of the AFE for approval if the Approval Path doesn’t have an approver with sufficient approval authority.
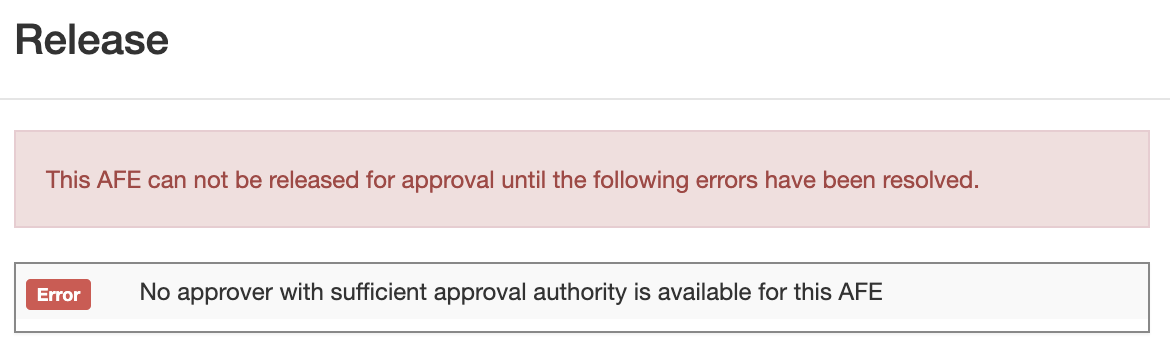
How can I limit which Approval Paths are selected?
The easy answer here is List Filters. By default we ship with a basic list filter that only shows Approval Paths where the Approval Path’s AFE Type matches that of the AFE (actually, we’re a bit fancier and allow for “wildcard” approval paths which show up for every AFE Type!).
Here is the default list filter rule on the AFE’s Approval Path field.

If you wanted to further segment your rules, perhaps based on AFE Area, you can add an Area list field to the Approval Path document (don’t forget to add an Area dropdown field to the Approval Path General custom tab), and then update your list filter like so:

How many approvers can I have in a path?
We’ve created 15 approver fields (meaning the max is 15), but we’ve only made the first seven fields active initially. If you need more than 7, you can just enable additional fields on the Approval Path document.
Does this support approving tiers? (Parallel Approvals)?
It sure does! The “Share Tier” fields mean that the approver shares the same approving tier as the user above. So this example here:
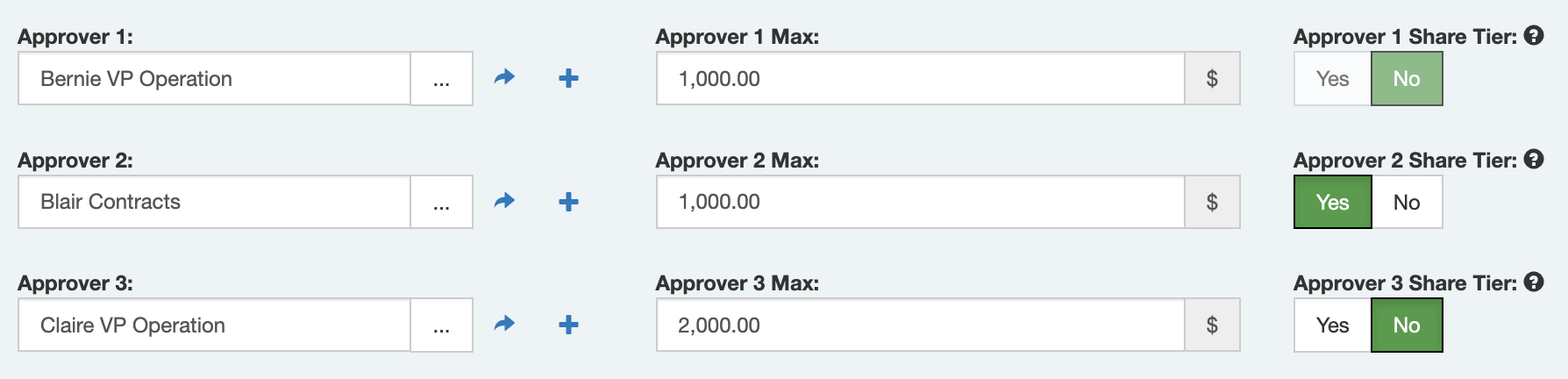
Would yield these approvers on an $1,500 AFE.

Does this mean that Blockly Approval Rules are going away?
Absolutely not. Blockly rules were created for a reason and are better at modeling certain types of approval rules. This new option is better for other types.
If there are no positions… how does out of office work?
There are positions, actually.
While approving positions are not part of the Approval Path rules we build, they are a requirement of Execute’s approval engine. To make this work, we automatically create positions for each approver. By default, these positions are named after the approver (i.e. user “Jimbo Jones” will automatically get a position created called “Jimbo Jones”).
If you’d like to see a more traditional position name on the AFE’s approval tab, you can add a new custom field
CUSTOM/APPROVING_TITLEto the user and fill that in. From that point onward, the newly created position rules will be named like “{Approving Title} - Jimbo Jones”.So, for out of office, our normal functionality applies. If “Blair Contracts” is out on vacation and delegates to “System Admin”, you’d see a record like this. You can clearly see who was supposed to approve it, and who actually did approve it.

How do I handle wildcard rules (“any area”)?
It depends, but if you are using list filters and/or release validation rules to restrict which Approval Paths are selected for an AFE, you can build that logic into the rule.
For example, a simple list filter like this would require that the AFE’s AFE Type match the Approval Path’s AFE Type (no wild cards).

But by adjusting it slightly, we can allow for an empty AFE Type on the Approval Path document to apply to AFEs of every type.

Can I use this and Blockly Position Rules?
You sure can! When releasing an AFE for approval, any approvers from the new-style Approval Paths are added first, followed by any approvers added by Blockly.
This allows you to add high-level approval rules (“President sees everything over $5M”) in Blockly and avoid adding them to every Approval Path… if you want… (of course, doing so makes reviewing the rules more difficult).
You may also choose to use Approval Paths in general, but use Blockly Position Rules for specific AFE Types that are too complex for Approval Paths.
-
We’ve added a new setting, “Allow User Delegation”, which allows users to delegate their AFE/Job review and approval duties. We’ve left this functionality off by default because we know that it doesn’t make sense for some organizations that want strict control over who a user selects to approve/review on their behalf. For environments that need this, however, it’s a quick flip of a setting and users will find the new option under their user menu in the top-right of their screen.
#afe
21.1.295
#334871
Out of Office Delegation
A frequently requested feature is now available: users can delegate their own review or approval when they’re away—without needing to go through a system administrator.
To enable this functionality, simply toggle the new setting:
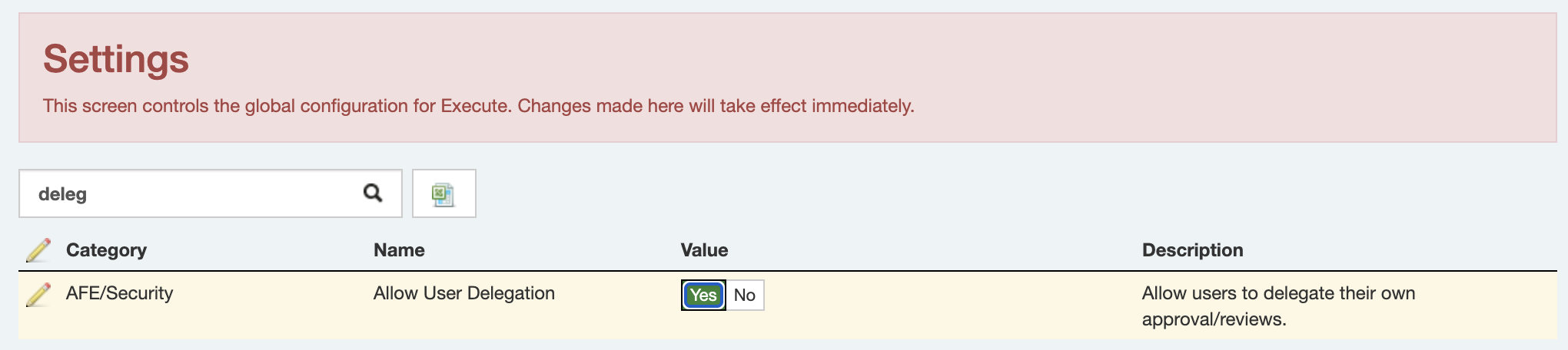
Once enabled, users will see a new “Out of Office” option under their user menu (top right):
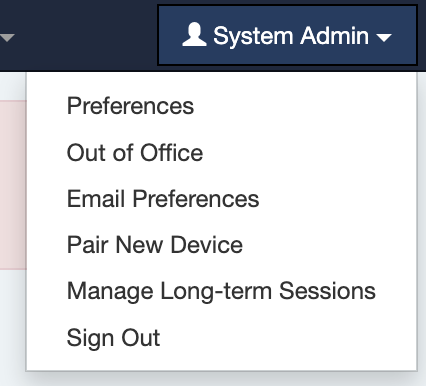
From there, users will be guided through a simple delegation wizard, similar to the one currently used by administrators.
Note: This feature is best suited for environments where users are trusted to choose appropriate delegates. At this time, there is no rule system in place to validate that the selected delegate has the necessary approval or review authority.
-
Execute has great little “+” icons next to list fields which are a quick shortcut allowing an authorized user to create a new value for that list and automatically select it. Just the thing when you go to create a new AFE, but realize nobody got around to adding that newly acquired asset to the list in Execute. This release improves upon this functionality by defaulting to the new record type’s first tab (rather than our currently non-user-friendly approach of generating a tab using the alphabetical list of all fields on the record). In addition, administrators can create a special “Quick Add” tab to streamline the experience.
#system
21.1.295
#335025
Improved Quick Add Experience
In Execute, list fields typically include a
+icon that lets users quickly create and select a new record of that type.Historically, the Quick Add pop-up form wasn’t exactly elegant—it displayed all fields on the new record in alphabetical order, which wasn’t always helpful.
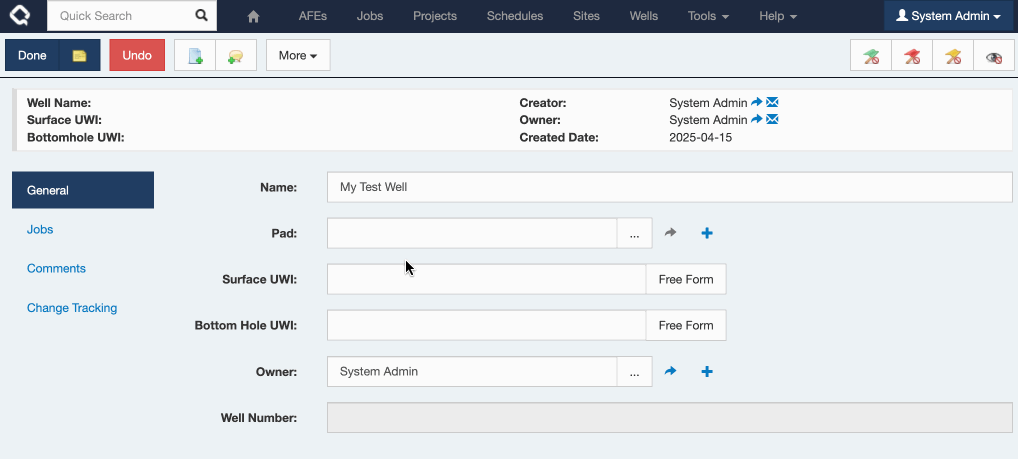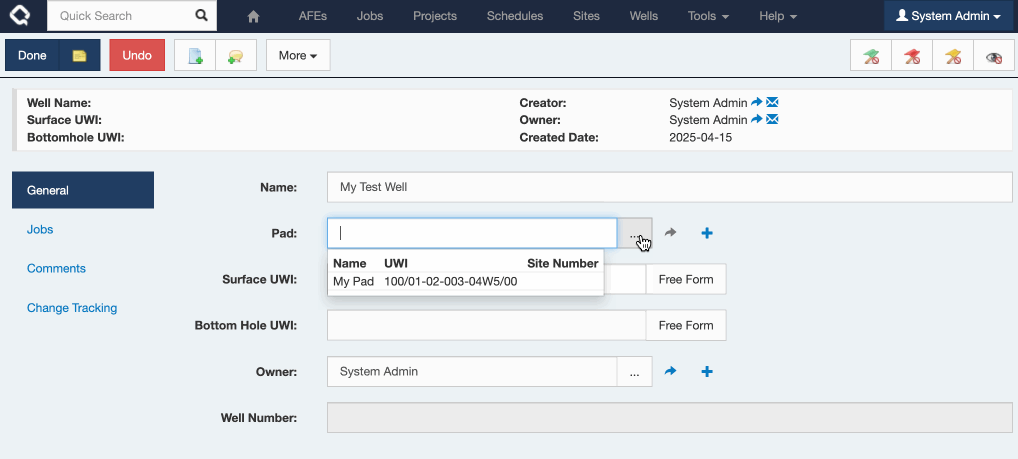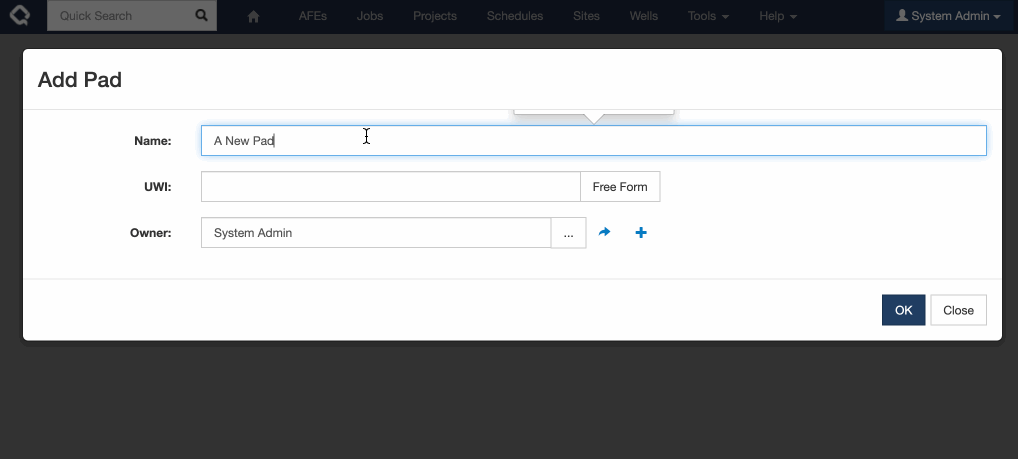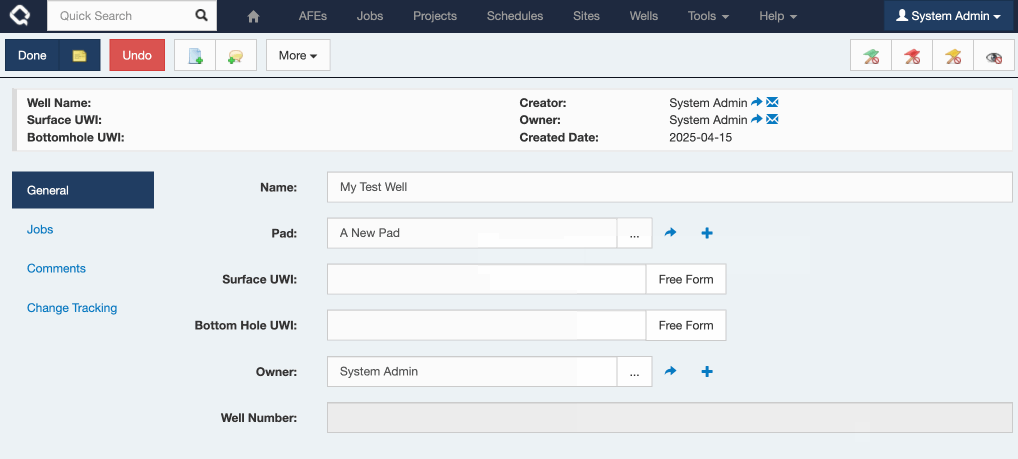
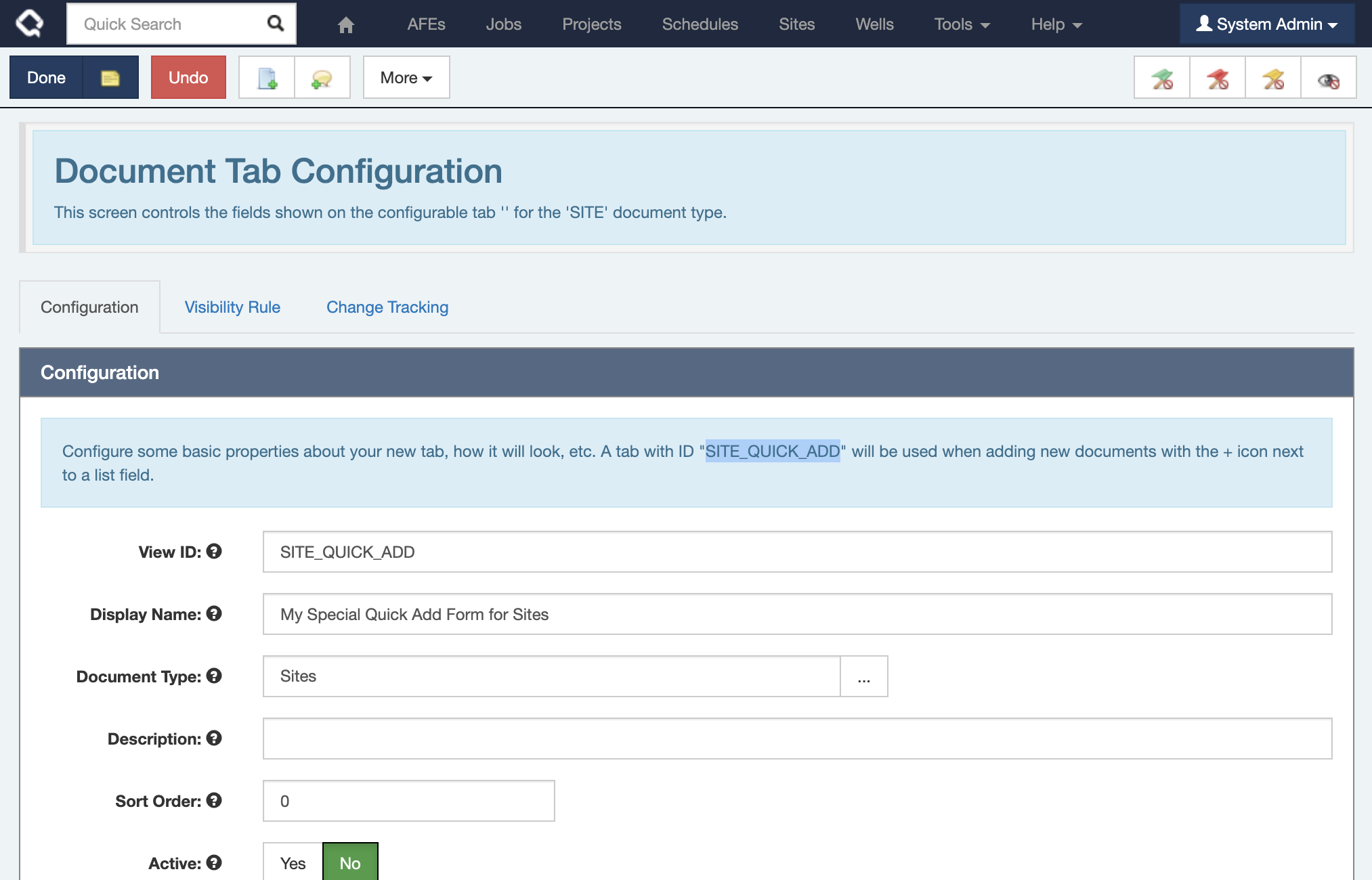
In this release, Quick Add now defaults to using the first (default) tab defined for that document type. It will only fall back to the alphabetical view if no custom tabs are available.
So now, adding a Pad from your Well looks a whole lot cleaner:
And if I’d like further control, you can create a special “Quick Add” custom tab and really dial it in!
-
Improved capability for referencing fields on other documents.
#system
21.1.281
#306214
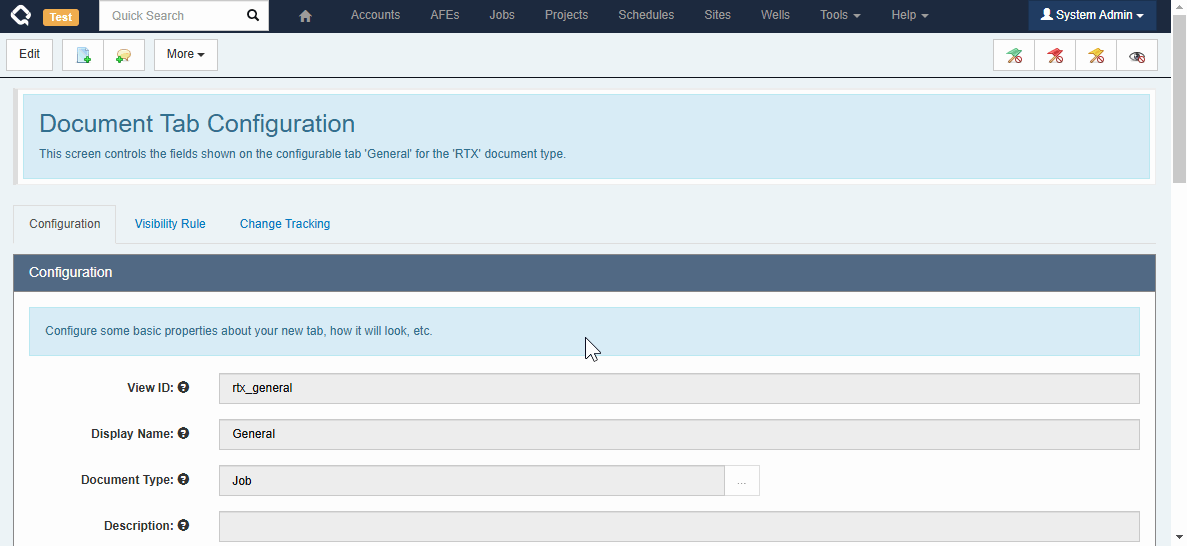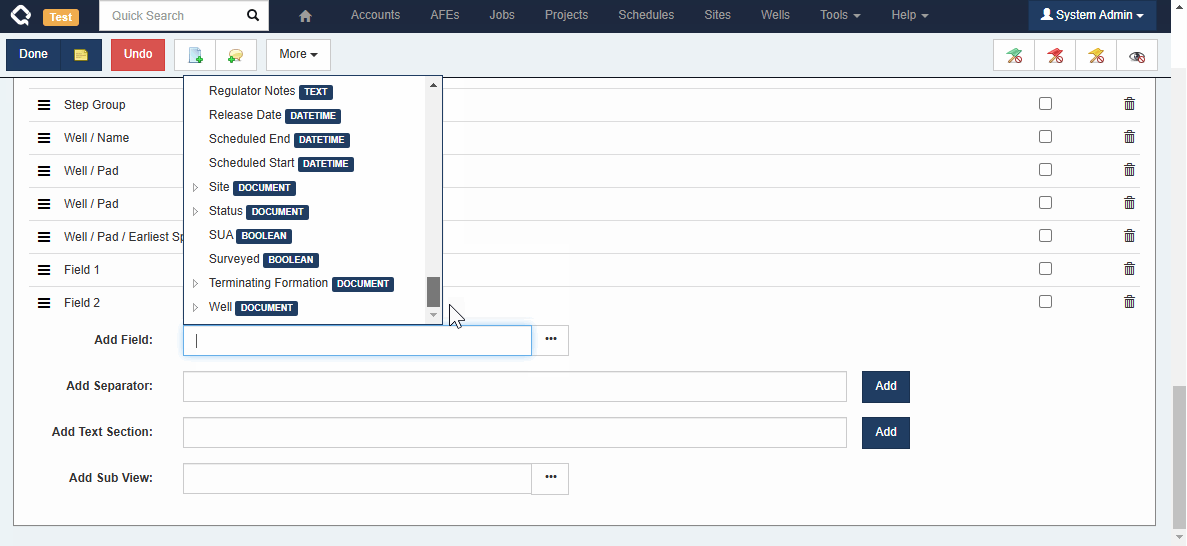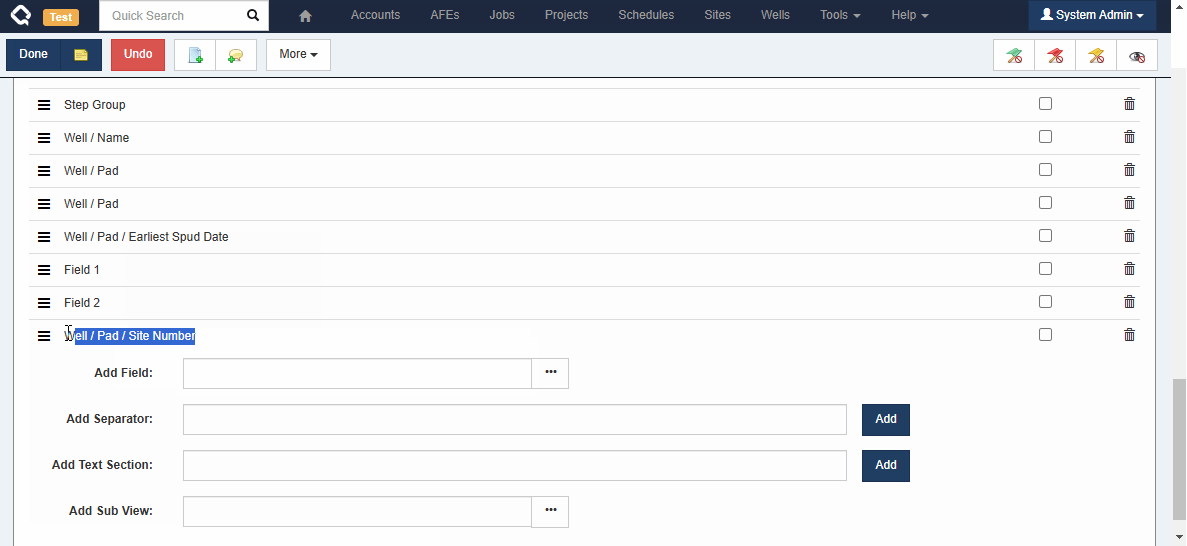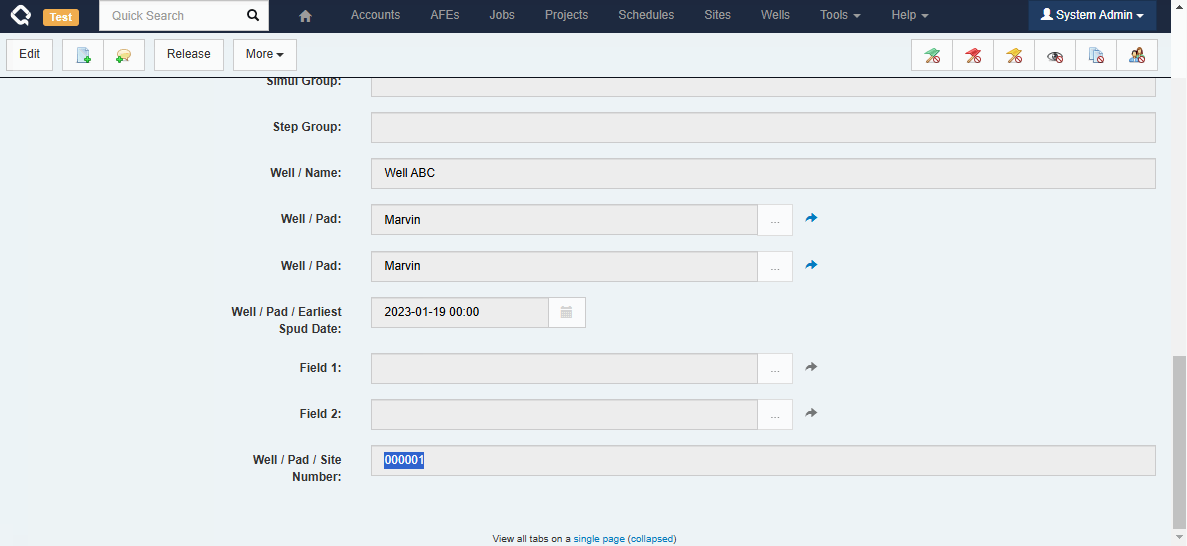
In many places throughout Execute, information from linked documents can now be included without requiring you to build calculated fields, etc. The examples below are primarily around Wells, Jobs and Pads but the functionality is available across any for any record type in Execute.
Browse Reports (User Facing)
Using our new column picker, everyone can now build reports that include/reference data from related documents.
Here is a quick example showing how to include Well and Pad-level fields on a Job report.
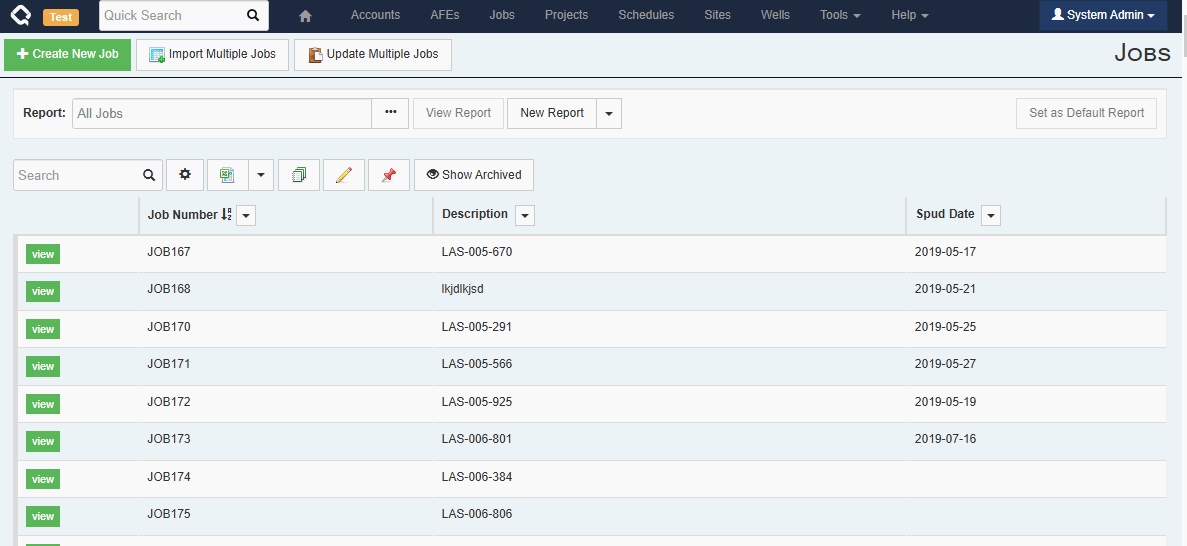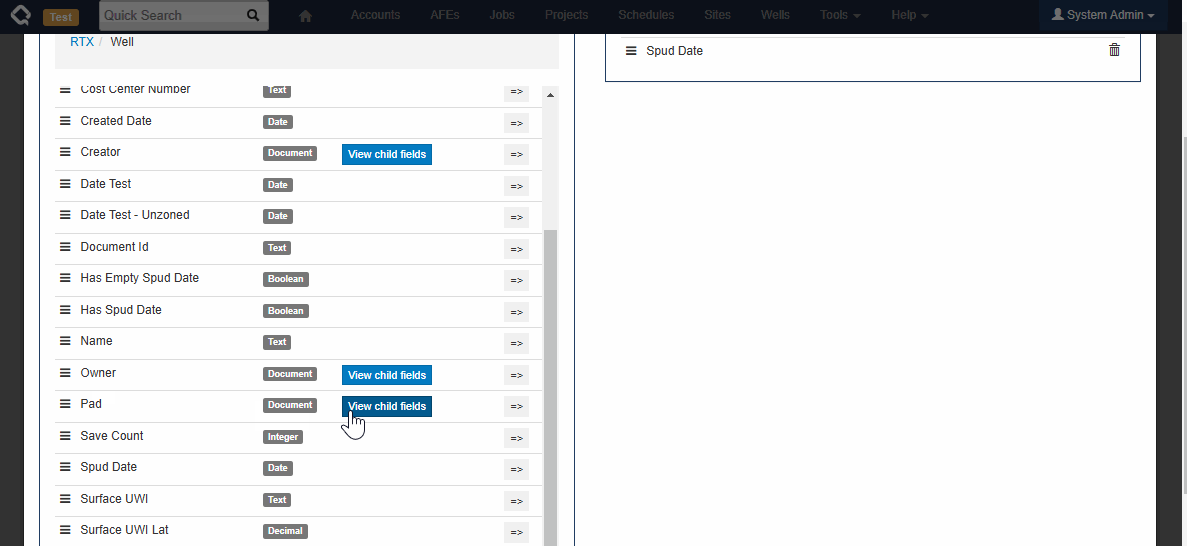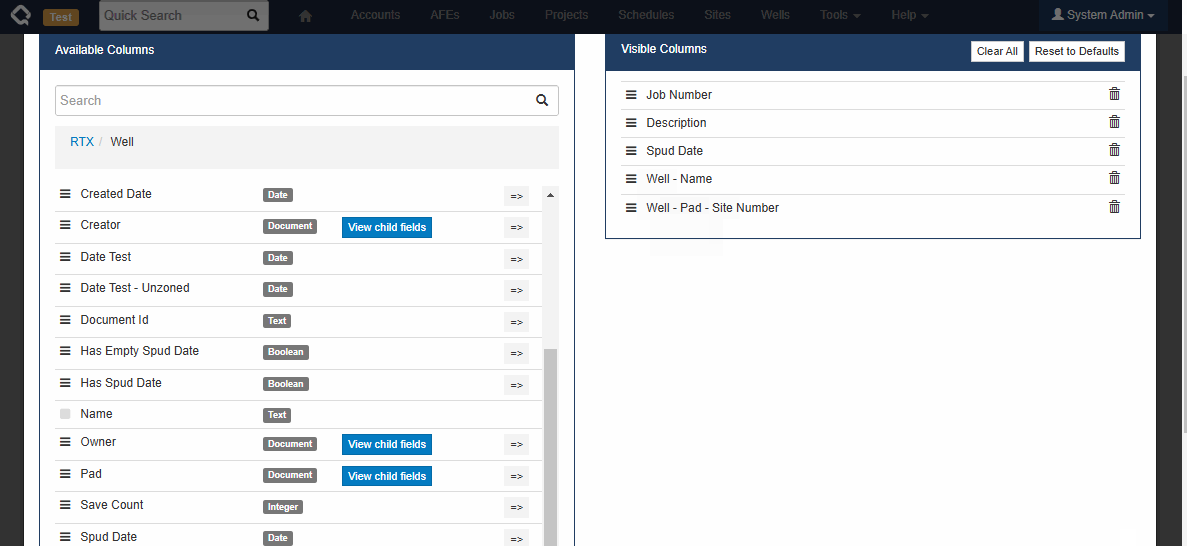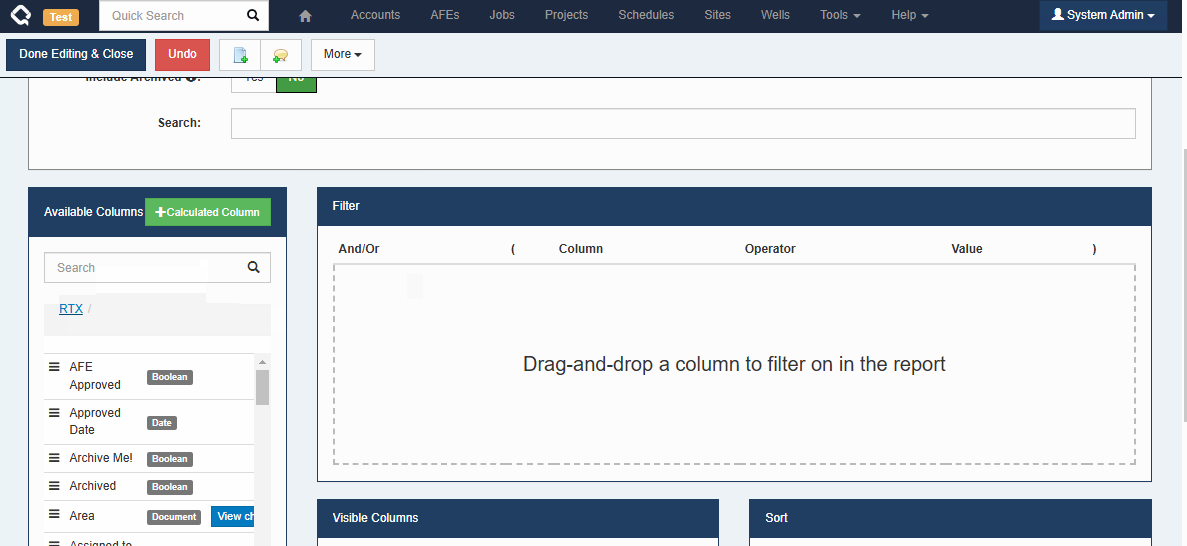
We always strive to minimize non-admin/end-user-facing changes to avoid the need to retrain users. In this case, while there is a visible change for the end-user, we hope the change is small and obvious enough that it won’t cause any confusion.
Custom Tabs
Administrators can also include fields from related documents when building custom tabs. For example, a Job custom tab can include fields from the linked Well or Pad for reference.
Note that currently, these referenced fields are NOT editable (i.e. you can’t edit a Well field from the Job), but we’re working on that!
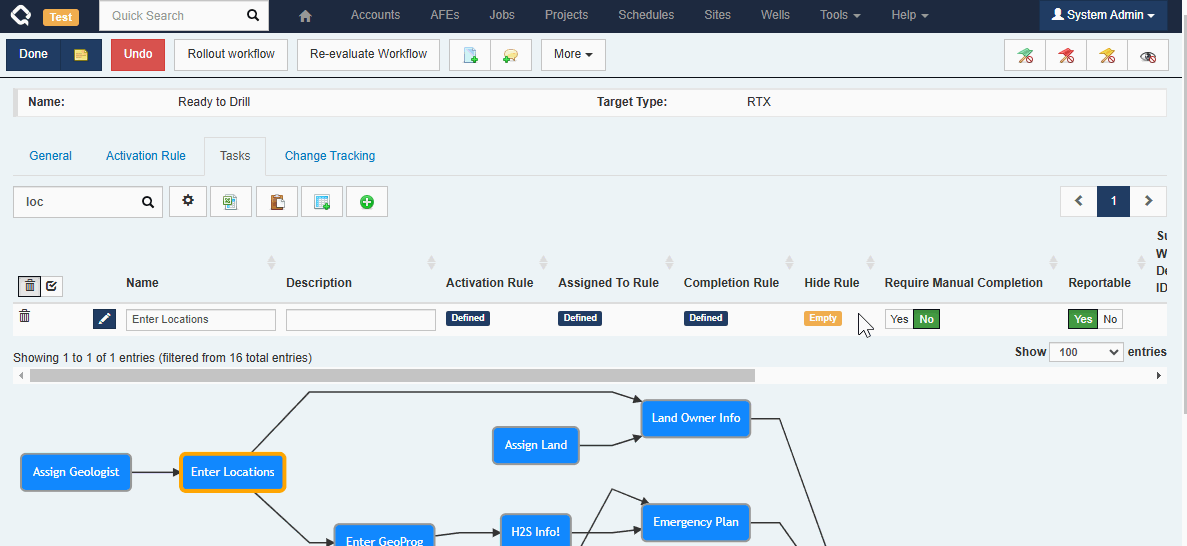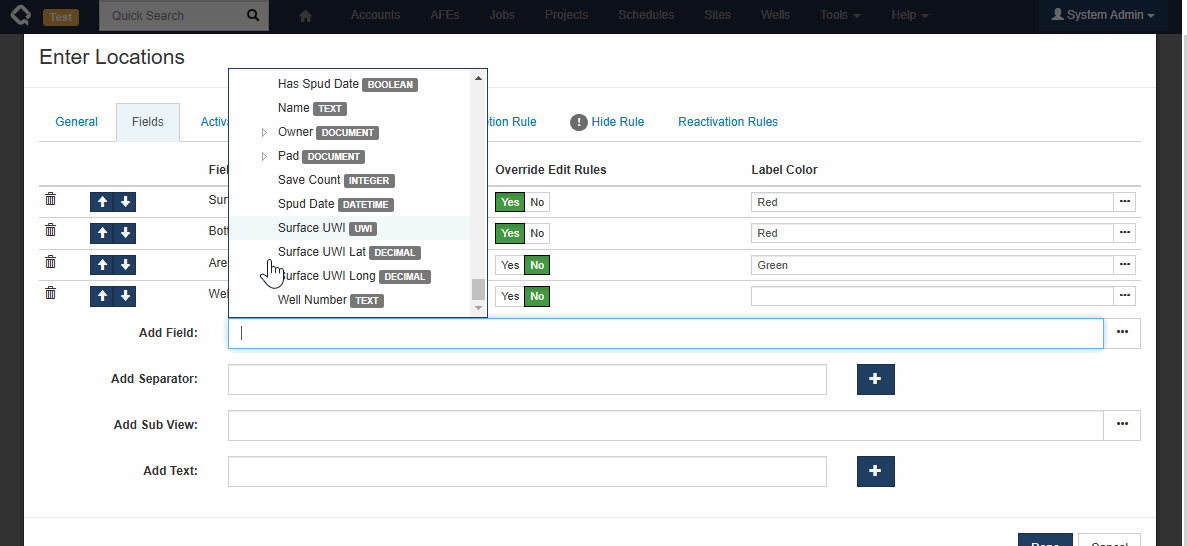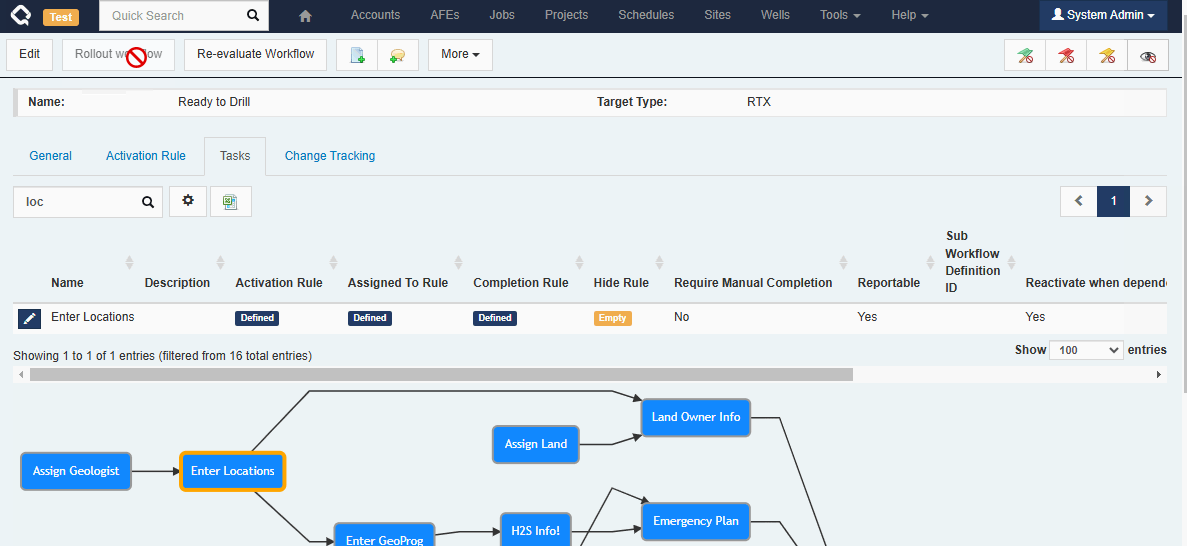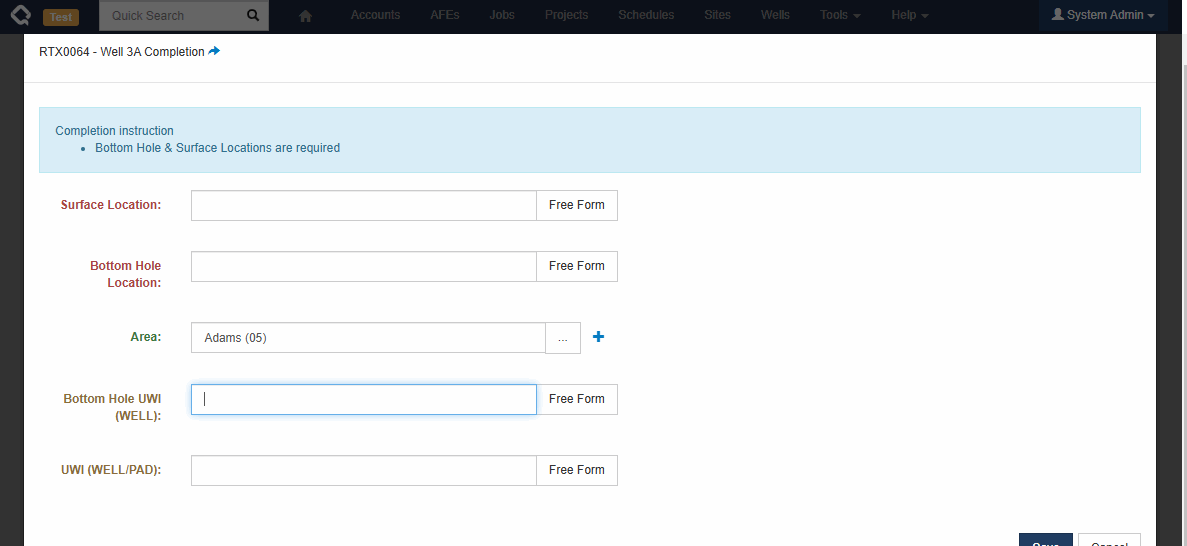
Workflow Tasks
Administrators can include fields from related documents on workflow tasks. For example, a Job-level workflow task can include fields from the Job, the Job’s Well, and the Job’s Well’s Pad! Unlikely Custom Tabs, these fields are all editable (assuming the user has the appropriate permissions).
Custom Business Rules (Blockly)
And, finally, you can do this when building custom business rules using Blockly too!
Execute used to offer similar functionality for specific references using our “Reference Fields” dropdowns. These fields have been replaced by the new (more capable) functionality, and any existing rules using the old Reference Fields should have been automatically updated to the new structure*.
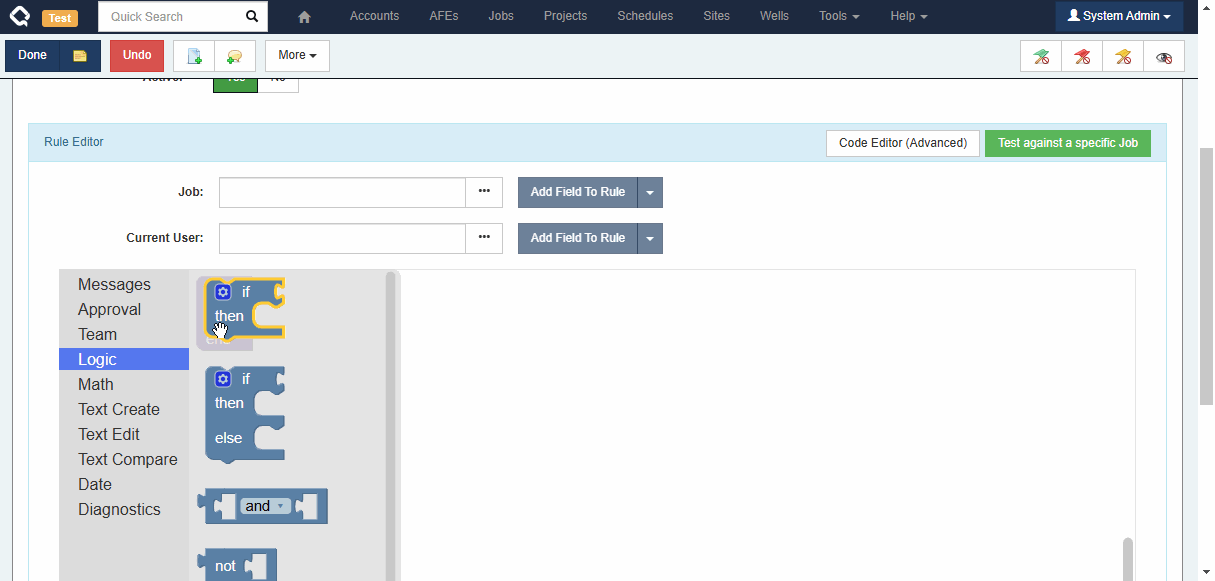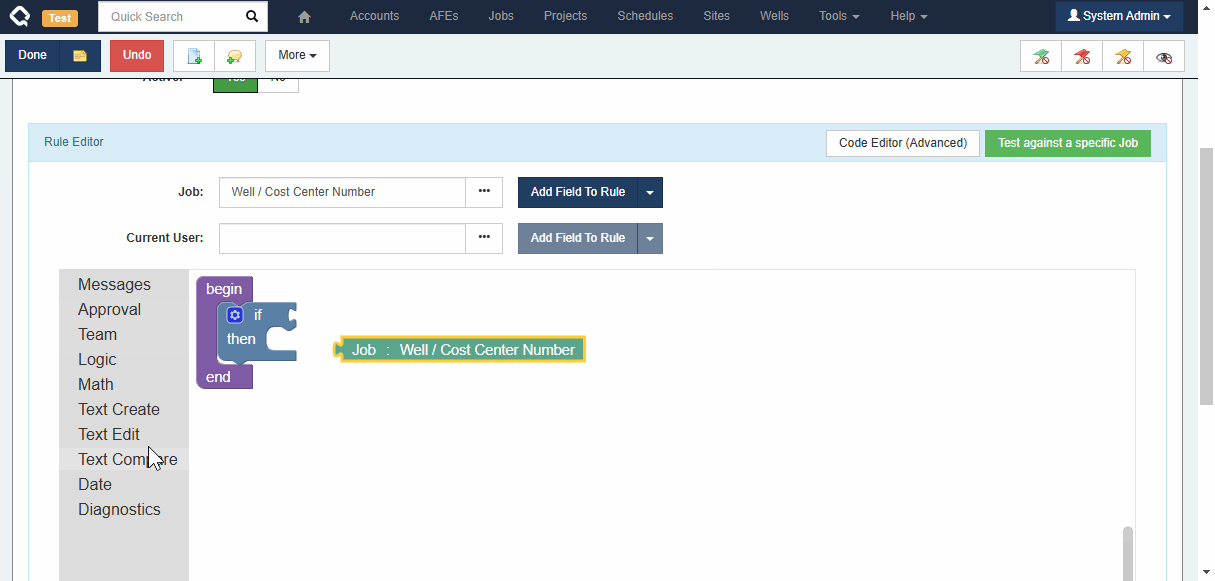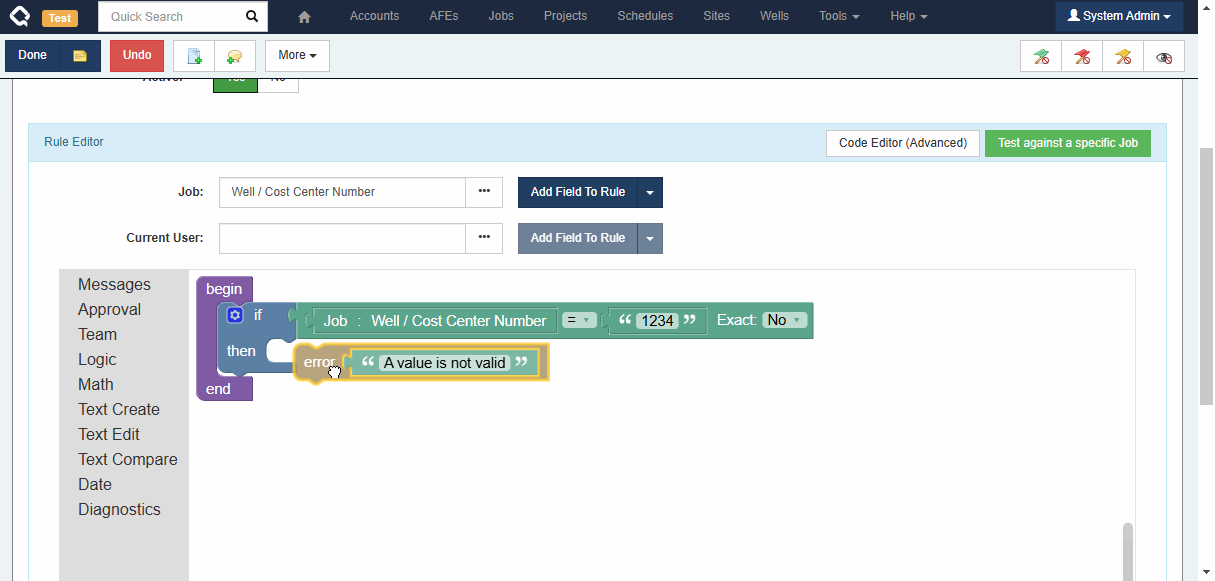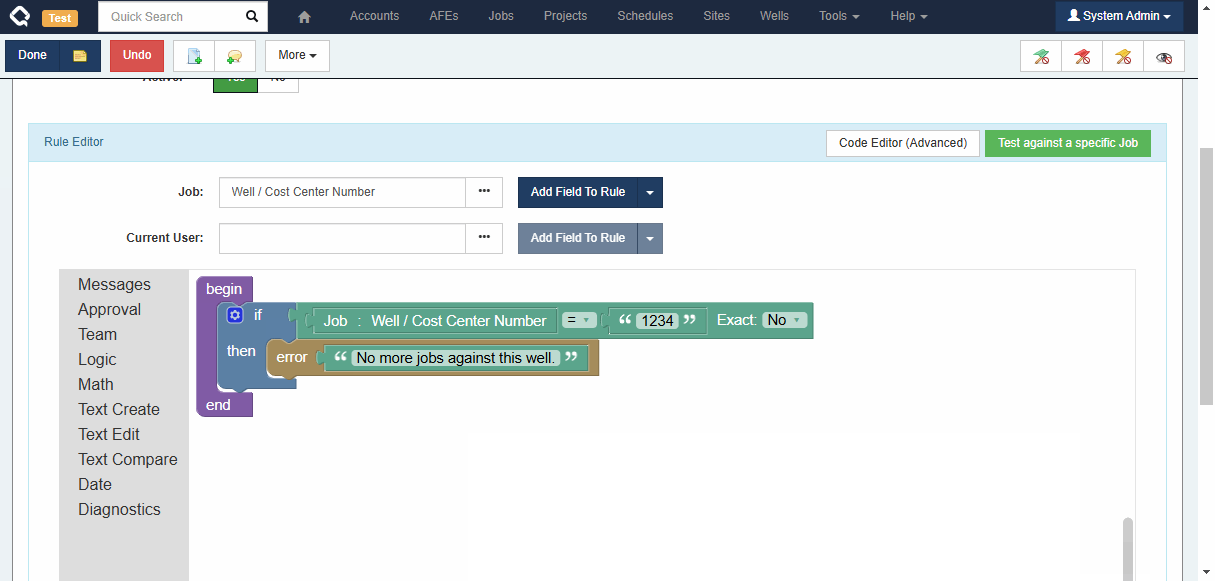
Note: The old Reference Fields did allow building some references which we consider problematic because their behaviour was unpredictable. We have removed support for these problematic relationship types. Existing rules will continue to work as they did before, but it will no longer be possible to create new rules of these types.
The following relationships are no longer supported.
- Project > Well
- Project > Site
- Site > Well
- Well > Job
- Site > Job
For clarity, the way to read an entry like “Well > Job” in the above list is that it is not valid for a Well-level report, workflow task, report, etc., to refer to a Job-level field. The reason is that a Well often contains more than one Job, and as soon as more than one Job is referenced, it is impossible to show a single value for a linked Job-level field. Previously, we allowed rules to be built like this, but they would silently stop working as soon as more than one Job was linked.
-
Added a new streamlined Document Fetch API as part of Execute’s Advanced Data Export offering. This API makes it easier to slurp bulk data out of Execute to populate an internal data warehouse, or similar.
#integration
21.1.273
#288479
Execute’s new Document Fetch APIs provide a streamlined way to bulk extract documents from Execute.
- A single streamlined API call vs. the Login > Run Report > Logout call for the current APIs.
- Returns ALL data for request documents in a nice friendly machine readable JSON form.
- Supports including calculated field values in the returned data (popular request from User Voice).
- Easily filtering to return only documents modified since a provided date (makes it much easier to keep a remove warehouse up-to-date).
Note: These APIs require the Execute Advanced Data Export (OData) module license.
More information can be found in our New Postman-based API documentation.
Enhancements
- The print dialog for non-AFE documents has been enhanced with search and select all capabilities. As well, you can select to generate a separate PDF file per form. The selections you make on the dialog are remembered for the next time you print a document. The downloaded PDF file will be named with the document’s display identifier and the form name. #ui 21.1.325 #362777
- The enhanced print dialog for non-AFE documents now allows you to select PDF attachments for inclusion in the PDF output or click on links to download non-PDF attachments. #attachments #ui 21.1.325 #363063
-
You can now suppress the Teams and Approvals tabs for a Job document. This will be useful for companies using advanced workflows instead of disciplines to gather information for a Job.
#ui
#well delivery
21.1.325
#361127
The Team and Approvals tabs can be turned off by adding the following to the
<castle>container inuser.config.To turn off the Teams tab:
<?define SUPPRESS_RTX_TEAM_TAB ?>To turn off the Approvals tab:
<?define SUPPRESS_RTX_APPROVALS_TAB ?> - Improved the select all functionality within table data selectors. There are now options to select all or select all on page. Footers in the selection modal show the number of selected rows from the total number available. #ui #plugins 21.1.325 #360453
- The UI character limits for comment fields are now consistent with the limits in the database. #ui 21.1.325 #359871
- Testing is complete for Databricks data selector and synchronization plugins. This functionality has been promoted from a beta version. #integration #plugins 21.1.325 #357137
- Final removal of legacy Angular library files. #system #ui #security 21.1.325 #350027
- Upgraded the DataTables javascript library to version 1.13. #ui #security #system 21.1.325 #357403
- We’ve improved file attachments by adding a progress meter to drag-and-drop uploads, enforcing a consistent 256MB file size limit, and showing clearer error messages when uploads fail. #attachments #ui 21.1.323 #359298
- Added extra diagnostic info to some internal error messages, making it simpler to understand what went wrong when data is missing or invalid. #workflow #system 21.1.323 #360005
- The Dashboard layout has been migrated from Angular to React. #dashboard #ui #system 21.1.321 #350026
- The RTD Partners table has been migrated from Angular to React. #ui #system #well delivery 21.1.321 #351443
- The Settings management has been migrated from Angular to jQuery. #admin #ui #system 21.1.321 #350022
- The Support Package page been migrated from Angular to jQuery. #admin #ui #system 21.1.321 #350020
- Added DOMPurify to sanitize Markdown rendering in areas like field-level help text and Message of the Day. This prevents scripts and raw HTML from executing within Markdown fields, improving security while preserving the existing Markdown experience. #security #ui #system 21.1.321 #357967
- A sample plugin and xslt file for the integration with Quorum Cost Accounting has been added to the plugins repository. #integration #afe #plugins 21.1.319 #357564
- A new alphabetical filter bar has been added to the Configuration page, making it easier for users to find specific configuration items. #ui 21.1.319 #357589
- In the Quorum balloting server, once a partner submits an “Approved” response, they can no longer clear it. If the approval was submitted by mistake, the partner must contact the ballot operator to have the ballot resent and their response cleared. #ui #balloting 21.1.318 #356538
- SharePoint authentication has been updated to use certificate-based authentication instead of username and password, aligning with modern SharePoint security standards. #integration #security #api 21.1.317 #356724
- The BallotUpload process now properly cleans up its temporary files after streaming rendered forms, helping keep the system tidy and preventing unnecessary file buildup. #system #performance 21.1.317 #296318
- The custom business rule configuration interface has been migrated from Angular to jQuery. #ui #system #security #admin 21.1.317 #350023
- The Comments view has been migrated from Angular to jQuery. #ui #system #security 21.1.317 #350025
- The Document Types management tool has been migrated from Angular to jQuery. #admin #ui #system #security 21.1.317 #350017
- The reminder time selection interface has been migrated from Angular to jQuery. #ui #system #security #admin 21.1.317 #350024
- Updated DataTables JavaScript from version 1.9.4 to 1.13 to address security concerns and improve compatibility. #security #system #ui 21.1.317 #352852
- The marked.js library has been updated to the latest stable v12.x, bringing improved security, better performance, and new features to Markdown rendering across the application. This update affects areas like the MOTD banner, help text, and help page viewer, ensuring a smoother and safer user experience when viewing Markdown content. #security #performance #ui 21.1.317 #354511
- On sign-in, Execute now automatically updates your user timezone to match your current browser timezone. Previously, it would prompt you when the browser timezone differed from the user timezone. #system #ui 21.1.316 #353437
- Document syncs now include the plugin source file name as the save comment, making it easier to identify the origin of changes. Instead of writing the filename in the comment text, it is stored in the designated source field for clearer tracking. #plugins #integration #system 21.1.316 #351021
- Added an emergency feature flag that allows you to stop loading database plugins if they cause issues, preventing situations where the app starts but documents can’t be saved due to a broken plugin. #plugins #system #admin 21.1.310 #351023
- Added new API Key renewal functionality and API to make it possible to routinely rotate API keys. #api #security #ui 21.1.310 #351519
- PDF locking has been disabled for generated AFE and Document forms to accommodate use cases like electronic signatures. #afe #attachments #system 21.1.310 #351314
- The year range for Estimate Periods on AFEs has been expanded from 4 years around the current year to 10 years. #afe #ui 21.1.310 #349732
- The document print action modal has been migrated from Angular to jQuery. This was part of our migration away from AngularJS and has no functional impact. #ui #security 21.1.310 #350013
- The Manage Forms tool has been migrated from Angular to jQuery. This was part of our migration away from AngularJS and has no functional impact. #ui #security 21.1.310 #350021
- Preview Approvers actions for RTD and RTX have been migrated from Angular to jQuery. This was part of our migration away from AngularJS and has no functional impact. #ui #security 21.1.310 #350016
- We’ve added new log messages to improve troubleshooting during database upgrades. #system #opsched 21.1.310 #346403
- The AFE Printing dialog has been simplified to make selecting partners and forms easier, with new options to generate and download individual PDFs per partner. You can now hide affiliates and electronic balloting companies from the print list, and generated filenames are more descriptive, including AFE number, partner name, and form name when applicable. Additionally, PDF attachments can be included in the final output for a more complete package. #afe #ui #attachments 21.1.310 #349606
- SQL Warehouse sync scheduling has been improved to allow intervals up to one day, with a new anchor hour ensuring daily or twice-daily syncs run at consistent, predictable times regardless of server restarts. #opsched #system 21.1.310 #351568
- Document Sync now takes non-exclusive (shared) locks on supported document types, increasing the chances that updates will succeed even when documents are open by other users. #well #integration #system 21.1.310 #351588
- The SQLite library has been upgraded to a newer version. #security 21.1.310 #350873
- The application has been updated to Angular 1.8.3 to mitigate multiple potential issues. #security 21.1.310 #349743
- Users can now renew or rotate their API keys to generate new secrets while keeping the same key ID, enhancing security by enabling regular credential updates. The renewal process includes selecting a new expiration period, and immediate invalidation of the old secret. #security #api #admin 21.1.307 #348493
- You can now drag and drop files directly into attachment fields to upload and automatically select them, making file uploads faster and more intuitive. This even includes (at long last) workflow task attachment fields!!! #attachments #ui 21.1.307 #347412
- The auto-release reviewer will now hold off on releasing an AFE for approval until all release validation rules are met. (NOTE: This means you’ll have to pay attention to your release roles as things like invalid overhead configuration will prevent the automatic release of AFEs.) #afe #workflow #system 21.1.307 #348585
- This release introduces a new plugin that enables CSharp-backed calculated fields, allowing more flexible and powerful custom calculations. Additionally, the Custom Document Action plugin has been enhanced with new post-action and redirect expressions. #plugins #workflow #system 21.1.307 #348121
- When viewing change history on large text fields (such as plugins) you’ll now see a colored coded “diff” view that makes it approximately 1,000,000 times (yes. Really) easier to spot the differences. #ui #system 21.1.307 #347436
- The target-date drag tooltip for activities has been improved to follow your mouse pointer instead of sticking in the schedule button bar, preventing annoying page jumps and making the experience much smoother. #ui #workflow #opsched 21.1.307 #348265
- The plugin editor now supports enhanced search functionality using CTRL+F, allowing you to find text beyond what’s currently visible on screen. #plugins #ui 21.1.307 #348282
- You can now clear temporary placeholder numbers on historically loaded wells and sites just like you do with AFE and RTx. #well #afe #ui 21.1.307 #348258
- The API Key authentication process has been overhauled to simplify integration with external systems. You can now use standard Basic Authentication headers with API keys to access Execute APIs without needing to manage session IDs manually. #api #integration #security 21.1.306 #347845
- If you’ve ever been driven to the point of madness because you open a plugin only to realize you aren’t in edit mode, this fix is for you. The plugin content is no longer a pop-up modal but now appears in a sleek new Plugin Details tab, making editing more intuitive and less frustrating. #plugins 21.1.306 #347741
- We’ve added special header colors for TEST and DEV environments to help you quickly identify which environment you’re working in. #ui #system #admin 21.1.306 #347398
- Smashleft Mode lets you quickly move activities as far left as possible within an OpSched row, eliminating whitespace without overlapping other activities or blackout periods. In addition, we’ve added keyboard shortcuts to switch between commonly used scheduling tools - just hover over a tool to see the shortcut used - For example, pressing SPACE while looking at a schedule activities the new shift left feature!). #opsched 21.1.306 #258790
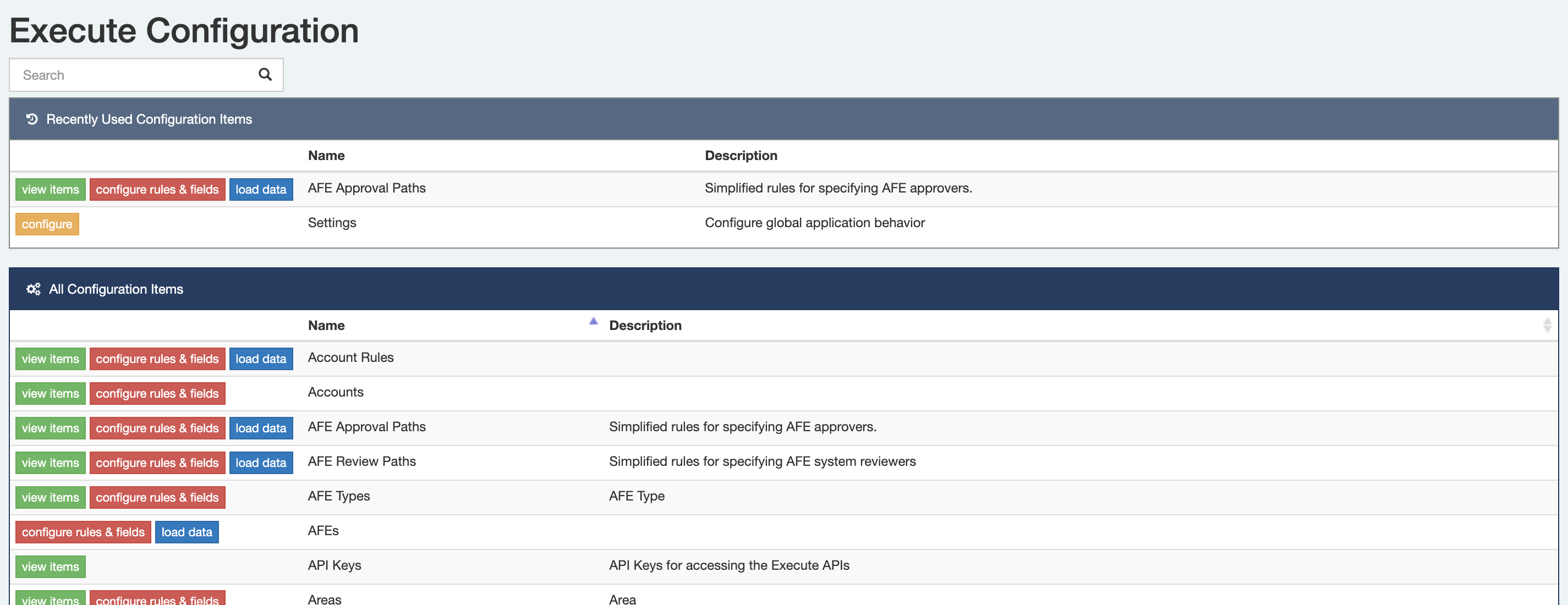
-
A Most Recently Used (MRU) list has been added to configuration screens, making it easier and faster for users to access their recently edited settings without hunting through the big list.
#admin
21.1.306
#347652
Some of us spend a lot of time in various settings/configuration screens in the app. The Configuration page now shows you a list of your most recently accessed configuration pages on the top so you can spend a whole lot less time searching!
- A new printing serializer has been added that includes linked documents, allowing printed forms that consolidate information from multiple linked documents. #afe #reporting #system 21.1.304 #340325
- Added new configuration settings that allow Execute to notify an external system after successful startup and before user-initiated shutdown. #system #integration #reporting 21.1.304 #343089
- The admin-facing field selection screen has transitioned from the recently released drop-down tree control to the same control used in the report field selector. The report selector version offers a better user experience and handles large numbers of fields more efficiently. #admin 21.1.298 #334455
- Updated the components used by the schedule printing functionality. #opsched 21.1.298 #338042
- We’ve improved the behavior in Execute’s new Approval Paths to better handle situations where multiple adjacent approvers have the same approval authority. #afe #admin 21.1.298 #338680
-
We’ve added a new formula function to create a new DateTime (
DateTime( "2024-05-01", "America/Edmonton")) and a new formula function to query if a workflow task is complete or hidden (i.e., needing attention or not). #formula 21.1.298 #340773 - We now support for List Filters on Workflow Tasks. #admin #workflow 21.1.298 #293061
- We’ve added icons to fields on Tasks and Custom Tabs to identify fields from related documents (vs. the document the user is currently working with). #system 21.1.298 #318332
- We’ve changed the default behaviour when viewing attachments to open in the browser/default application instead of downloading them. This is much more consistent with other web-based applications. Users who want to download the file can right-click and “Save As”. #ui 21.1.296 #338037
- The Integration Agent now supports connections to Snowflake (for Document Sync purposes). #integration agent #integration 21.1.296 #339388
- Execute’s unique value validation rule now works with UWI-type fields. #system #afe 21.1.296 #338517
- Upgraded Snowflake library to the latest and greatest. #system #security #integration 21.1.296 #338212
- If you’d like to see your primary document types (those in the top toolbar) in a specific order and have been annoyed at how prefixing them with “1.”, “2.”, … made everything else in the application look a bit wonky… good news. We’ve added a new configuration setting that allows you to set the sort order! #system 21.1.296 #338259
- We’ve lowered the batch size limit when exporting Execute data to Snowflake / Azure SQL to help eliminate issues with large documents like Schedules causing excessively large batches. #integration 21.1.296 #337950
- We’ve relaxed the rules a bit for account matching between Execute and ODW. So if your Execute account numbers are formatted like “100 / 234”, but you have “100 .-=-. 234” in ODW, you’ll be pleased to know that the integration will work just fine. #integration #wellez 21.1.296 #337090
- Improved error logging around login with OIDC to make troubleshooting easier. #system 21.1.296 #337130
- Inactivated the old Parent RTD field. If you’ve gone to the effort of migrating from the old RTD to the shiny new Jobs (RTx), you don’t want to see that smelly old Parent RTD field anymore! #well delivery 21.1.296 #336929
- Removed legacy actuals/field cost helper views from new databases. Existing databases are unchanged. #system 21.1.296 #333389
- Ever want to clear the date from a project activity? Now you can! #budget 21.1.296 #334073
- We’ve improved the Due for Forecast filter, ensuring that project owners can more reliably see projects that need their attention. #budget 21.1.296 #335791
- We’ve improved the Min/Max formula functions to work with date-type fields, and to have more sensible handling of null (empty) values. Note that with the new changes “Min(1,null,2)” will now return “1” whereas it used to treat the null as a zero and would have returned “0”. If you need this old behaviour, you can wrap the values with the coalesce function “Min(1, coalesce(null,0), 2)”. #formula 21.1.296 #338039
- Support for importing recurring/rental costs from WellView. Currently this behavior is off by default but it can be opted in if you rely on these costs. We will be enabling this by default in a future release. #peloton #integration 21.1.295 #335145
- We’ve turned off the old (and we’re talking really old) linked files to attachments migration. This feature was slowing down startup in some environments and at this point we think everybody who would switch over already has. If it’s needed, it’s a mere setting tweak away. #attachments 21.1.295 #335525
- It took us a couple of years to roll out the rename of WellEz to On Demand Well Operations within Execute, but we finally did it. Hilariously, however, we did so two weeks before we decided to stick with WellEz after all. This update brings back the much loved WellEz name. #integration #wellez 21.1.295 #335780
- We’ve made some backend changes to pave the way for the coming Quorum Electronic Balloting service, which will modernize the balloting process and use a heck of a lot less paper. #afe 21.1.295 #334262
- The AFE Estimate loaders now support loading phase-based AFE estimates, which is pretty nifty, if you need them! #afe #admin 21.1.295 #336870
- Added a new “Capital Actuals” column to Schedule Activity report types. #opsched 21.1.293 #333238
- We’ve added an optional flag to prevent pushing historical forecast start dates to Val Nav. #budget 21.1.293 #333842
- System restart requests are now added to the audit log. #system 21.1.293 #333843
- We’ve trimmed the columns down in the list of available columns when using Import/Update Multiple from the Browse Screen to just the updatable columns. This keeps the list much shorter (making it easier to find the column you are looking for), and speeds everything up. In addition, we no longer prefix column names with the Additional Storage Table name since that was never something end-users should be exposed to. #system 21.1.292 #333626
- Execute has a great integration with Quorum’s On Demand Well Operations (ODW) software, ensuring alignment between field staff and head office. Unfortunately, we were a tad retro and still referred to it as WellEz, which hasn’t been its name for a couple of years. We’ve updated the occurrences of WellEz within AFE Navig… err… Execute to reflect our new product naming. #integration 21.1.291 #258545
- We have continued upgrading the various column selection screens throughout the application (workflow definition tasks, field cost entry and AFE wells) to make them more consistent and eliminate a legacy component. #system 21.1.291 #317218
- Execute will now ensure that we don’t exceed database-level maximum row-size constraints when adding columns to custom tables. #system 21.1.291 #330990
- While the ASCII arrow (=>) in our new column selection screens would appeal to the computing hipsters in the crowd, we figured we should replace it with a proper icon instead. #reporting 21.1.291 #332237
- We’ve added two new fields to Execute to make building/maintaining your printed forms a bit easier (for us, if we’re being honest). Partners now have a “logo” field, and users now have a “signature” field, which can be used instead of baking your various logos and signatures directly into the forms themselves. This makes things a bit easier to maintain over the long haul. #reporting 21.1.291 #332291
- Additional configuration flags are now included in the startup logs to assist with troubleshooting and support. #system 21.1.291 #332294
- We’ve improved the scrollbars when viewing the diagram on really wide workflow definitions. #workflow 21.1.291 #333081
- Added a new “Updated Capital” column to the “Schedule - Activity” report type. This new column will return updated capital from the Budgeting and Forecasting module for the activity (splitting it between multiple activities if required). This is useful for exporting updated capital to an Excel-based Enersight well list. #enersight #reporting 21.1.287 #328760
- ODA integration credentials are now automatically encrypted if entered in plaintext (this is entirely a Quorum thing, but it is captured here to ensure we don’t forget!) #integration 21.1.287 #329060
- Add a new schema endpoint to our Fetch API to allow retrieving the structure of Execute data. #integration 21.1.287 #330385
- Upgraded Snowflake library to mitigate potential security vulnerability. #security 21.1.286 #329078
- Added a new optional “Net Project” field to Projects which ensures that all forecasting/actuals on that project are Net $ (useful for bucket-type projects). #budget 21.1.286 #328293
- We have improved how we store configuration parameters for integration with On Demand Accounting to streamline troubleshooting for Quorum Support. #system 21.1.282 #306741
- Execute, our installer, and the helper utilities are now digital signed by Quorum. #security 21.1.280 #293676
- Added a 6 month option for API key lifetime. #api 21.1.280 #316723
- Updated .NET framework to .NET Core 8. Updated many of our 3rd party libraries to the latest versions. #system #security 21.1.278 #293070
- Updated the Reporting/Browse API to make the filter parameter optional. #integration 21.1.278 #310598
- Added a “DOCUMENT_TYPE” hint for Document Reference fields to Execute’s JSON serializer. This improves Snowflake/Azure SQL Warehouse Exports and the new Document Fetch APIs. #integration 21.1.278 #311108
-
Major improvements to SQL Warehouse to improve performance, error recovery and reliability. These enhancements require a manual update step
#integration
#manual step
21.1.277
#285281
Execute’s Data Warehousing feature has received many updates:
SQL Warehouse
- We have removed the
NORMALandMATERIALIZEDoptions for the creation of helper views since they were not-performant with larger datasets. We added a new optionTABLES_AUTO(the new default, and our recommendation for most cases) which will similarly ensure that the helper tables are kept current automatically. - We have added support for breaking very large documents (typically only seen with Schedules) into smaller chunks. To enable this, the
EXECUTE_DOCUMENTStable has a newchunkcolumn. If you are queryingEXECUTE_DOCUMENTSdirectly, you may need to adjust your queries to handle this correctly (When querying normal fields, filter to chunk=0. When querying child tables, include data from all chunks). If you are querying our automatically created helper tables, this work has been done for you. - To avoid issues where restarting Execute could take a very long time, Execute will no longer wait for a sync to finish on shutdown but, instead, keep a highwater mark of successfully sync’d records. After restart, and on the next automated sync, Execute will publish any records modified since that stored highwater mark.
- Fixed behavior when Deleting and Undeleting records.
- To avoid excessive replication of data, the
EXECUTE_DOCUMENTS_LATESTtable no longer includes the data from the latest records. Queries relying on this table will need to join onEXECUTE_DOCUMENTS.
Snowflake
- We have added support for breaking very large documents (typically only seen with Schedules) into smaller chunks. To enable this, the
EXECUTE_DOCUMENTStable has a newchunkcolumn. If you are queryingEXECUTE_DOCUMENTSdirectly, you may need to adjust your queries to handle this correctly. If you are querying our automatically created helper tables, this work has been done for you. - To avoid issues where restarting Execute could take a very long time, Execute will no longer wait for a sync to finish on shutdown but, instead, keep a highwater mark of successfully sync’d records. After restart, and on the next automated sync, Execute will publish any records modified since that stored highwater mark.
- Fixed behavior when Deleting and Undeleting records.
Mandatory Manual Upgrade Step
Because of the changes made in this update, administrators must manually perform the following steps after upgrading Execute.
- Replace your SQL Warehouse or Snowflake plugin with the latest version from
plugins_available - Verify that the
Create Viewssetting is set appropriately (for SQL Server, we strongly recommendTABLES_AUTO) - Remove all Execute created objects in Execute’s Data Warehouse schema (
EXECUTE_DOCUMENTS,AFE,PROCESS_EXECUTE_DOCUMENTS,...). - Run the
Schema Publishersynchronization task. - Run the
Document Publishersynchronization task.
- We have removed the
-
Execute will now prevent password-based logins (login screen, APIs and OData) for environments which use Windows single-signon or Okta/OIDC.
#integration
#security
#manual step
21.1.277
#306539
Execute will now correctly prevent passwords from being used in environments configured to use Single Sign-on. This change has the potential to prevent users from accessing these SSO environments if they were relying on a username and password instead of the SSO mechanism.
This affects environments…
- using OKTA or OIDC for SSO
- using our legacy Windows login mechanism where the
Authentication Typesetting is set toWINDOWS
This means that:
- Users will not be able to login with a user-specified password in these environments.
- Login screen
- APIs
- OData
- Users will not be able to set a password. The password changing feature will be hidden from the user’s profile.
- Administrators will not be able to set a user’s password from the user management screen.
Any integrations using Execute’s API or OData should transition to using Execute’s safer API Key mechanism.
If you require the use of user-specified passwords in your SSO environment (NOT RECOMMENDED), you can override this new behavior by setting the new
Allow User Passwords When Federatedsetting. - Those of you wishing to bulk accept the autogenerated forecasts from the Update Project Forecasts screen now can. #budget 21.1.276 #161329
- Instead of typing things like “6d 12h” for a duration in the scheduling module, you can now type “6.5”. Additionally, the Export to Excel button always exports using the more Excel-friendly decimal days. #opsched 21.1.276 #302484
- Execute’s integration logging now includes support for logging calls NDJSON APIs (such as our own Fetch APIs). #system #integration 21.1.275 #296342
- Updated default DynamicDocs configuration file. #integration 21.1.275 #300773
- Added a new ‘Flags’ configuration item which can be used to suppress sending specified document types to a remote Data Warehouse. #integration 21.1.275 #302797
- Updated default configuration file for ODA integration. #integration 21.1.275
- Performance improvements when importing field costs from WellView and SiteView. #integration 21.1.275 #303107
- Improvements to calculated field performance for formulas that involved a divide by zero. #performance 21.1.274 #291058
- Browse reports (and many other report tabs) now support frozen titles, and columns using the new pushpin icon. #reporting 21.1.274 #296096
- Upgraded 3rd party library (underscore.js) to eliminate a potential security vulnerability. #security 21.1.274 #298303
- The new Show Field Usage function takes a while to work on very large record types. We’ve added a loading bar so that you won’t be left wondering, “Is it working?” #admin 21.1.273 #288972
- Updated HTTP caching headers to improve page load performance across the system. #system #performance 21.1.273 #288982
- Added additional guidance on the Plugin management screens to help administrators avoid common mistakes. #admin 21.1.272 #288483
- Improved error messages with Quorum OnDemand Accounting (ODA) integration. #integration 21.1.272 #290415
- Added support for new concurrent operational scheduling licenses. #opsched 21.1.271 #270672
- We’ve made improvements to the Integration Agent’s auto-update mechanism to make it more reliable for organizations with restrictive firewalls. #integration 21.1.271 #279370
- We’ve made some improvements to the error messages returned by our Integration Agent so that troubleshooting is a whole lot easier when things don’t go according to plan. #integration #valnav 21.1.270 #265027
- We’ve significantly improved the import speed for new activities on a busy schedule. In our test of importing 7,300 rows, we reduced the import time from 4.5 minutes to a brisk 7 seconds (a time savings of one metric coffee break!). #performance #opsched 21.1.270 #268392
- A bit of spring cleaning on the Integration Agent to ensure things keep running smoothly. #integration agent 21.1.270 #268543
- To keep Execute’s Job Scheduling feeling snappy, we’ve limited the number of rows shown in the Job Hopper to 1000. Users will see a warning if they are seeing a partial result set, and searching will still search all rows and just return the (maximum 1000) matching rows. #performance #ui #opsched 21.1.270 #269387
- We’ve reduced the volume of schedule data we read from the Execute server on each schedule change. This will substantially improve the performance of operational scheduling for large schedules and users with high-latency Internet connections. #performance #ui #opsched 21.1.270 #269388
- We’ve seriously reduced the amount of data loaded, and the number of API calls made when loading a tab in Execute. This has the effect of substantially improving tab loading/switching performance, especially for very large (many custom fields) documents and users with high-latency Internet links. #performance #ui 21.1.270 #274567
- Execute’ Support Package Generator is great for sending a copy of your environment’s configuration to Quorum for help. Unfortunately, generating the support package was quite slow for certain configurations. We’ve made some improvements to the speed and memory usage for these configurations. #performance #system #admin 21.1.270 #275762
- Execute’s Data Warehouse feature ensures Execute data is efficiently replicated in an external AzureSQL or Snowflake. Sometimes, however, if you made a pile of changes in Execute, syncing those changes into the warehouse could take a bit of time. If you tried restarting Execute while that was happening, it would apparently hang without any obvious indication of why. We’ve added some logging to make it easier to see what’s going on. #performance #integration 21.1.270 #275780
- Document Synchronization and Bulk Loads could perform poorly when dealing with very large numbers of records with a unique validation rule (such as PARTNERS, ACCOUNTS, …). In one environment with ~150k partners, the system would take many seconds to process each partner. With this enhancement, that same environment is loading records at a blazing 300 pps (partners per second). #performance #integration 21.1.270 #279727
- We’ve made some improvements to responsiveness when pasting large amounts of data from Excel (using our import/update multiple record functionality). #performance 21.1.270 #280994 #280995
- We’ve continued to clean-up and finesse our Data Selector sample configuration files to make them easier to understand and implement. #plugins 21.1.270 #281351
Bugs
- Fixed an issue where Mermaid diagrams on the Tasks tab of the workflow definition would fail to render when the text size exceeded the allowed limit. #ui #workflow 21.1.325 #361653
- Performance of the Jobs tab for Wells and Sites has been improved, and a loading progress indicator has been added. #well delivery #performance #ui 21.1.325 #361640
- Performance of the My Active Tasks widget on the dashboard has been optimized and a loading progress indicator has been added. #dashboard #performance #ui 21.1.325 #362304
- Improved the efficiency of some database queries that are run during service startup. #performance #system 21.1.325 #359874
- Fixed an issue where tables in an email reminder were not rendering correctly. #email 21.1.325 #361495
- Fixed a “DocumentHandle not found” error on workflow tasks when multiple fields on a referenced document are used and certain combinations of them are non editable. #workflow 21.1.324 #362694
- Fixed a timezone comparison issue that prevented position rules with start dates near the current time from activating correctly on jobs. This ensures delegation and position rules now trigger as expected regardless of timezone differences. #well delivery #system 21.1.323 #358838
- The connection to the Dynamic Docs API now restricts attribute values to a maximum length of 255 characters. #plugins 21.1.323 #357818
- The ODA DOI selector now correctly handles identical duplicate records. #ondemand #plugins 21.1.323 #361364
- “Primary Well” fields were missing from the Update Multiple UI. They have returned! When updating multiple records you can once again select the Primary Well fields. #afe #ui 21.1.323 #360400
-
Fixed the issue where fields with a
CUSTOM/path could not be edited on referenced documents. #workflow 21.1.323 #357763 - Corrected the error message when a workflow task referred to an inactive field. #workflow 21.1.323 #358372
- Fixed an issue where editing fields on referenced documents causes intermittent save failures and the SQL Warehouse sync to fail with a duplicate key error. #workflow 21.1.323 #358841
- Fixed an issue where the workflow task UI is not editable when it only contains fields from referenced documents. #workflow 21.1.323 #358973
- Attachments now download successfully from attachment fields belonging to other document types. #workflow #attachments 21.1.323 #357763
- Attachment fields in workflow tasks now behave consistently with other fields, including the ability to change label colors and display shared field and lock icons. #workflow #attachments #ui 21.1.321 #358788
- The fields shown in the document header will wrap long lines of text instead of overlapping the next field. This issue would have been most noticeable on smaller displays, like mobile devices. #ui 21.1.321 #357820
- Fixed an issue where file attachments in attachments tables did not sort correctly by date. #attachments #ui 21.1.321 #352736
- The sample events_approval_snapshot.config plugin no longer causes the service to enter recovery mode. #system 21.1.321 #359680
- Increased caching and managed threading to prevent cases where large sets of updates (through Import or Update Multiple) can cause excessive CPU and memory usage. #system #performance 21.1.321 #358871
- Email notifications will now send when a partner status synchronization from Execute Electronic Balloting occurs and results in the status of the AFE changing to Fully Approved or Partner Rejected. #afe #balloting #email 21.1.320 #360038
- Fixed an issue where some file attachments would fail to appear, due to a file being locked. A service restart would be required to bring them back and no errors were shown on the Attachments tab to indicate that there was a problem. Now an error message is displayed on the Attachments tab and further information regarding the locked file can be found in the server log or the support package. . #attachments 21.1.319 #358257
- Resolved an error when generating a forms package per partner, when the forms are configured to print only for certain partners. #forms 21.1.319 #353941
- Workflow diagrams will now generate if a task name in a sub-workflow, or the sub-workflow name, includes an ampersand (’&’). #workflow #ui 21.1.319 #356452
- Field paths displayed on the Required Fields tab in the Discipline configuration page now include the slashes. #ui 21.1.319 #349687
- Fixed an issue where the application’s built-in emails were failing. #email 21.1.319 #358794
- Addressed a performance issue when loading Wells using the spreadsheet loaders. #well #loader #performance 21.1.319 #356132
- Fixed an issue where data selectors would not load data to select. #ui #integration 21.1.318 #357323
- Fixed an issue where the Send to Partners modal had a very narrow column for the list of selectable forms. #ui #balloting 21.1.318 #357243
- Fixed date parsing error when setting the Out of Office period when the date format on the server is set to display days first. #api #system 21.1.318 #355591
- Fixed the searching and sorting in the tasks grid of a workflow definition. #workflow #ui 21.1.318 #357326
- Reverted the data tables library change from version 21.1.317. #system #ui 21.1.318
- Improvements to error message reporting when the Integration Agent encounters a TLS certificate error. #security #integration #system 21.1.317 #353967
- The AFE Project Allocation Report now correctly allocates actuals and field costs in systems where an account-level filter is not in use. #afe #reporting #budget 21.1.317 #351841
- Fixed an issue where the Auto-release process was not updating the ‘Next Reviewing Position’ and ‘Next Approving Position’ fields. #workflow #system 21.1.317 #355395
- Fixed a critical issue where selecting blocks in Blockly was not working in the latest versions of Chrome and Edge. #ui #system 21.1.317 #356620
- Fixed an issue where the browse reports screen incorrectly showed a calculated field edit icon next to every field. #reporting #ui 21.1.317 #355095
- Fixed an issue where very long field names could break the Excel sheets downloaded from the browse screen. #reporting #attachments #system 21.1.317 #353469
- Fixed an issue where Custom Tab Text Sections did not support multiple line input, allowing users to now enter and display text across several lines as intended. #ui #system 21.1.317 #295772
- If you set your preferred date format to ‘mmm dd yyyy’ (a reasonable choice), you can now actually enter dates in that format like you’d expect. #ui #system 21.1.317 #349499
- Fixed an issue where emails appeared distorted or improperly formatted when viewed in Gmail Web, ensuring a cleaner and more consistent email display for users. #email #ui 21.1.317 #353687
- Error messages now display correctly without incorrect HTML escaping, making it easier to understand issues when they occur. #ui #system 21.1.317 #353996
- Fixed errors occurring when copying data from PostgreSQL to MSSQL using the database tool, ensuring smoother and more reliable data transfers between these systems. #integration #system 21.1.317 #355211
- The Job Report dropdown in the Schedule Editor now only displays Global reports, making it easier to find the right report without clutter from other report types. #ui #reporting #opsched 21.1.317 #306212
- The response date for a partner now correctly clears when the status is removed, ensuring your data stays accurate and up to date without any extra clicks. #workflow #ui 21.1.317 #354221
- Fixed an issue where slashes in text sections and separators within the workflow task modal would hide the text or separator. #workflow #ui 21.1.317 #353990
- We’ve resolved a performance issue affecting workflow reporting, so generating your reports should now be faster and smoother, even when handling large data sets. #workflow #reporting #performance 21.1.317 #355718
- Workflow tasks now correctly disable fields when you don’t have edit rights. #workflow #ui #security 21.1.317 #354592
- Workflow task reminders now correctly send notifications even when the underlying workflow definition was deleted. #workflow #email #system 21.1.317 #355065
- Approval and review paths now default to the ‘Always’ view rule, saving an annoying and unnecessary step when implementing them. #workflow #ui #system 21.1.316 #351887
- Increased the maximum number of primary document types that could be shown in the header (before being turned into an annoying dropdown) from 7 (I’m sure it made sense at the time) to 10. #ui #system 21.1.316 #352475
- Fixed an issue where slashes in text sections and separators within the workflow task popup broke our user interface. #workflow #ui 21.1.316 #353990
- When AFE is automatically reviewed, there is no review user associated with the Auto Release review position. This empty user caused an error when reporting on the “Reviewed by me” field. #afe #reporting #workflow 21.1.316 #353139
- When we tried to lock down the ‘Pair New Device’ menu item for federated environments, we locked it down a bit too much. It was missing and has now been restored. #ui #system 21.1.310 #352072
- Fixed issue with bulk loading AFE estimates using out Data Loaders. #afe #loader #integration 21.1.310 #351087
- Fixed an issue where if base AFE of a revision or supplement was incorrectly allocated to a project there was no way to fix the mapping. #afe #budget #system 21.1.310 #350440
- Fixed an issue where DataHub/SQL Warehouse Schema Publisher could generate foreign key name collisions. #integration #system 21.1.310 #351164
- Fixed a minor JavaScript error that appeared on the AFE Review Status page when opening a newly created AFE. #afe #ui #system 21.1.310 #351391
- The Workflow Task graph has been adjusted to reduce clutter caused by too many nodes or overly large node labels, making it easier to read and navigate your task flows. #workflow #ui 21.1.310 #350288
- The integration agent availability status now correctly displays in the UI, resolving the issue where it always showed as “unavailable.” #integration agent #ui #integration 21.1.310
- Fixed an issue where Execute’s workflow diagrams would break if tasks contained markdown. #workflow 21.1.309 #349858
- Fixed an issue where the installer could not correctly detect user SIDs for Group Managed Service Accounts (GMSA), ensuring smoother installation and configuration when using these accounts. #system #admin 21.1.308 #349480
- Fixed an issue where creating blank format-rules on reminders could break sending other reminders. #workflow #system #ui 21.1.307 #340405
- Fixed an issue where leaving the time zone field blank would stop the entire reminder sending process. #workflow #email #system 21.1.307 #340841
- Added detailed logging for failures in the Integration Agent to help identify and troubleshoot connection issues more effectively. #system #integration agent 21.1.306 #341746
- Fixed an error that occurred when editing integer fields from the browse page if those fields were used in calculated fields. #formula #system 21.1.306 #347917
- Fixed a frustrating issue where you couldn’t build custom tab fields that pulled fields from a User, Partner, or Account document. #system 21.1.306 #347507
- Fixed an issue where invalid XML in the agent’s databaseConnections.config file would fail silently, ensuring users are now properly alerted to configuration errors to prevent unnoticed connection problems. #integration agent 21.1.306 #347232
- Fixed a typo in the Bulk Update modal. #ui 21.1.306 #346923
- Azure logging now correctly respects environment variables for its settings, ensuring that the EXEC_AZURE_INSIGHTS_CONNECTION variable properly overrides configuration files during initialization. #system #integration 21.1.304 #340068
- The custom table subview now correctly appears on the Workflow Task pop-up ensuring users can now edit individual fields and tables. #workflow #ui 21.1.304 #346070
- The installer now correctly applies permission changes during headless (scripted) installs, ensuring that in-app updates run smoothly without permission issues. This fix addresses upgrade failures caused by permission adjustments only running during interactive installs, improving reliability for automated update scenarios. #system 21.1.304 #344594
- The OpSched named license user check has been fixed to exclude support users, ensuring only actual licensed users are counted. This prevents support accounts from incorrectly consuming named licenses. #opsched #system 21.1.304 #346358
- The support package no longer leaves behind temporary directories after use, keeping your Execute server clean and clutter-free. #system 21.1.304 #342833
- Fixed an issue where the well data header overflowed its container, improving the display and readability in the user interface. #ui #well #system 21.1.304
- Fixed an issue with the HttpMultipartParser to ensure reliable processing of multipart HTTP requests, improving stability and preventing errors during file uploads or form submissions. (This is a behind the scenes thing that only affected those of you uploading attachments via. our APIs) #system #api 21.1.304 #344588
- Fixed issue that was causing Execute to generate invalid license IDs on Windows-based servers. #system 21.1.299 #343124
- Resolved an issue where you could create invalid AFE history by manually calling the Supplement AFE API and failing to save the historical (supplemented) version of the AFE. This only applied to those writing code against Execute’s APIs to supplement AFEs. #afe #api 21.1.298 #339273
- We’ve added the “Document Display Identifier” back into the field list in Execute’s custom business rules (Blockly). #admin 21.1.298 #339421
- Resolved an issue where list filters wouldn’t immediately clear an invalid value but would, instead, clear on save. #system #admin 21.1.298 #341220
- Resolved an issue where the FieldInfo report would show an error in the Field Type column for fields that had been deleted. #admin 21.1.298 #341516
- Resolved an issue where Custom Business rules failed to show custom fields on the AFE’s well table. #admin 21.1.298 #338359
- Resolved an issue where the order of Workflow Task fields could break field permissions. #workflow 21.1.298 #334861
- Resolved an issue where adding a List Filter could sometimes freeze the UI. #system #admin 21.1.296 #336708
- Resolved an issue where the Bulk Export plugin could cause Execute to fail to start if the destination folder didn’t exist. #plugins 21.1.296 #338041
- Resolved issue where Custom Business rules failed to show custom fields on the AFE’s well table. #afe 21.1.296 #338359
- Resolved an issue preventing AFEs from being exported to WellEz. #afe #wellez 21.1.296 #339020
- Resolved an issue where the database upgrade would fail in environments without an AFE_TYPE. #afe #system 21.1.296 #339024
- For those of you rocking the commas in your report names, you’ll be glad to know that the bug preventing you from exporting those reports to Excel is now resolved. #ui 21.1.296 #296011
- We’ve resolved an issue where workflow task fields would sometimes jump mysteriously for workflows loaded with the historical loader. #workflow 21.1.296 #334868
- We’ve resolved an issue where we created new versions in the ACTUALS_DOC_V table much more often than we should have and, at the same time, ensured that AFE actuals and field costs will now move across into your external data warehouse. #system #afe 21.1.296 #335140
- Resolved an issue where foreign keys on Postgres-based Execute databases were missing “on delete cascade”. #system 21.1.295 #299474
- Resolved an issue where fields in a Blockly loop variable would fail to show the nice field name. #system 21.1.295 #326878
- Restored the helpful “User Has Permission” and “User In Group” features that allowed you to build custom business rules based on the user’s permissions. #system 21.1.295 #332811
- Resolved an issue where users were unable to add new attachments using our legacy Linked Files behavior. #afe 21.1.295 #334654
- Resolved an issue where referencing DOCUMENT_ID in custom business rules could cause the rule to break. #system 21.1.295 #334940
- Resolved an issue where frozen column headers were inadvertently showing up on the Execute dashboard (and looking rather broken while doing it). #dashboard 21.1.295 #335045
- Resolved an issue where creating a specially named attachment and then deleting it would break attachments for that parent record (all attachments mysteriously disappear). We won’t mention the specific naming here because the temptation to try it is probably too great :) #attachments 21.1.295 #335282
- Resolved an issue where Blockly rules on a workflow task would sometimes “jump tabs” when making edits and switching back and forth between completion rules, assigned to rules, etc. #workflow 21.1.295 #335624
- Resolved an additional issue with loop variable numbering in Blockly. #system 21.1.295 #336479
- Resolved an issue where invalid Blockly rules could be saved if the loop iterator variables had a name conflict. #system 21.1.295 #336583
- Resolved an issue where drop-down fields in Blockly rule editors would occasionally fail to load. #system 21.1.295 #336601
- Resolved an issue with the item# counter failing to increment when building loops in Blockly. #system 21.1.295 #336773
- If the terms “MAWL” and “GOA” are meaningful to you, this update fixes the issue with historical approvers breaking the approval rules. #afe 21.1.295
- We now prevent the bulk field importer from loading empty formula fields as these are invalid and cause other issues in the system. #system 21.1.293 #333745
- We’ve added the “Document Id (match on)” back to Update multiple from Excel from the Browse screen. #reporting 21.1.293 #334756
- Resolved a terrible issue where removing a task from a workflow definition could cause all other task dependencies in that workflow definition to be cleared out (requiring you to manually add them back to each task). #workflow 21.1.291 #250285
- Resolved an issue where deleting a task and rolling out the updated workflow definition would raise mysterious “The given key…” warnings for any instances where that task had already been completed. #workflow 21.1.291 #264449
- Cleaned up a minor issue with our new column selectors where it was showing the underlying document type “RTX” instead of a nice use-facing “Job” in the breadcrumbs. #reporting 21.1.291 #328492
- We’ve fixed a frustrating issue with the workflow task editor that caused changes to the graphical rules (completion rule, activation rule, etc.) to be lost when switching tabs. #workflow 21.1.291 #332743
- To our users who prefer to see their dates in the format “dd/mm/yyyy”, we are deeply sorry. For YEARS, it seems, we’ve had an issue in our date entry controls where a user whose preferred date format was set to “dd/mm/yyyy” would see the month and day flip-flop each time they clicked into a date control (for dates where the day was also a valid month). #system 21.1.291 #332951
- Adding insult to injury for those who prefer the “dd/mm/yyyy” date format, we discovered that format would break the “Workflow” tab. This has been resolved. #system 21.1.291 #333059
- Resolved an issue where changes made to a Blockly rule after using the “Code Editor” mode were not saved properly. #system 21.1.291 #333156
- Fixed an issue where Audit events (such as an admin force approving an AFE) were not showing on the Change Tracking tab as intended. Note that the changes made were always captured in the change history, and the audit event itself was still captured and visible in the global audit log. #system 21.1.291 #333327
- Resolved an issue where a database could become invalid if adding a new field to the database took longer than our default timeout of 30 seconds. This timeout would cause the field to be added to the main table, but not be added to the history table, causing future save operations to fail. This only occurred for truly monstrous custom tables. #system 21.1.287 #329663
- Resolved an issue where adding a custom table to an additional storage table would break the change history tab for all current documents of that type. #system 21.1.287 #331117
- Resolved an issue where environments with large numbers of fields were taking an uncomfortably long time to verify that fields on startup (in the specific case what was taking about ten minutes now takes a fraction of a second). #system 21.1.287 #330810
- Resolved an issue where adding a custom link to the help menu would cause the release notes links to disappear. While we were at it, we also added support for “mailto:” links in the help menu making it easy for users to launch a new email to your internal Execute support team from the Execute help menu. #system 21.1.286 #328756
- Password fields are now correctly hidden from browse report column selection screens (don’t worry, passwords were never exposed in this way). This prevents an issue where OData reports would crash if they mistakenly included a password column. #system 21.1.282 #328646
- Fixed a super annoying issue where the screen would sometimes automatically scroll when interacting with dropdown fields 😡. Primarily, this was noticable when selecting a report on a Browse screen with large numbers of visible columns. #system 21.1.281 #327877
- Fixed an issue where adding an additional storage table that included the name of its parent table would cause an issue. #system 21.1.280 #303945
- Fixed issue where you could bulk import a reporting calculated column whose ID exceeded the maximum allowed length. #system 21.1.280 #308428
- When exporting the AFE to ODW, the description is now trimmed to 50 characters. #integration #wellez 21.1.280 #325648
- Fixed default placement of the monthly columns on the Field Cost Entry screen to directly left of the total column. #afe 21.1.280 #325711
- Fixed an issue where changing a UWI from DLS to API would leave the old Lat/Long in place. #integration 21.1.280 #319947
- Fixed an issue where UWI formatting was inconsistently applied when loading UWIs using a sychronization or data selection. #system 21.1.280 #323966
- Fixed a typo (missing “>”) in the sample “Expense Forecast” widget. #plugins 21.1.278 #263772
- Fixed wording of the AFE’s “Change Company” feature on the Partners tab. The title now lists the company’s name, instead of just repeating the word company twice. #afe 21.1.278 #267358
- We fixed an issue where the new browse screen update feature (a.k.a. pencil mode) would fail when trying to set a dropdown list field to null (no value). #system 21.1.278 #292810
- Resolved an issue where users could not set values for Additional Storage Table fields on records created after a new Storage Table was added but before restarting Execute. Upon upgrade, the system will fix records that are currently experiencing this suboptimal behavior. #system #admin 21.1.278 #304858
- Resolved issue where the Due for Forecast filter was including projects it shouldn’t. Also added a “please wait” indicator when bulk accepting forecasts. #budget 21.1.278 #307384
- Resolved an issue where Execute wasn’t closing temporary files correctly. This caused some unexpected (but harmless) errors to show up when restarting the service. #system 21.1.278 #307541
- Resolved an issue when copying a database from Oracle to SQL Server where the Oracle database contained dates before 1753 (Yes… 1753…). These unusual dates occassionally snuck into the database through database scripts and imports, and would cause the upgrade to crash. #system 21.1.278 #307776
- Fixed issues with the Due for Forecast filter’s identification of projects with new or updated actuals. #budget 21.1.278 #307941
- We resolved an issue where deleting a user who had been delegated field cost entry would cause the service to fail to start. #afe 21.1.278 #307963
- Resolved an issue where Execute’s startup data validation routines could occasionally run slowly enough to timeout. #system 21.1.278 #308330
- Deleting a user now deletes all sessions associated with that user. #system #security 21.1.278 #310101
- Added time zone configuration to our sample table_data_selector plugin. #plugins 21.1.278 #310187
- Resolved an issue where an undeleted document wouldn’t be visible in the Browse screen until a service restart. #system 21.1.278 #310725
- Fixed an issue with custom fields not showing when creating workflows on User and Partner documents. #workflow 21.1.278 #314180
- We now ensure that the global system user can see all documents, regardless of visibility rules, to avoid issues with synchronizations. #system 21.1.276 #300925
- Execute would run out of memory when trying to show really huge views (20k+ activities) in Operational Scheduling. We’ve adjusted that so that Execute will load a smaller set of activities and alert the user that they are viewing truncated results. #opsched #performance 21.1.275 #279726
- Resolved an issue where the Net Supplement columns would be incorrect on AFEs using Estimate Phases. #afe 21.1.275 #297871
- Increased AzureSQL timeout when clearing the TEMP table to allow Execute to recover from a very large failed sync. #integration 21.1.275 #300922
- Resolved issue with Project reforecasting when spend curves are being used. #budget 21.1.275 #301600
- Fixed an issue where a misconfigured plugin would cause the menubar to fail to load. #system 21.1.274 #245798
- Fixed an error where users were unable to update activity duration on activities in Execute’s operational scheduling module. #opsched 21.1.274 #289480
- Improved the clarity of error messages raised when a Document Link Summary view is misconfigured to make finding and fixing the mistake easier. #system 21.1.273 #253151
- Fixed an annoying issue where switching schedule views would sometimes jump to a different view a few seconds later. #opsched 21.1.273 #288470
- Fixes to the export of AFEs to Peloton-hosted SiteView (2.1 APIs). #integration #peloton 21.1.273 #291362
- We resolved an issue where we were inadvertently creating automated document links to Project Snapshots. #system #budget 21.1.273 #291678
- Resolved issue where Blockly rules referencing the now deprecated Advanced blocks would fail to compile. #workflow 21.1.272 #283239
- Fixed issue where NET estimate was not correctly exported to Quorum OnDemand Accounting (ODA). #integration 21.1.272 #290332
- Fixed an annoying issue where the route for review comment box would clear itself when you clicked outside of the comment box. #afe 21.1.271 #228443
- Fixed an issue where document synchronizations would create multiple rows if the document’s visibility rule excluded the AFE Navigator Service User. #integration #system 21.1.271 #237917
- We’ve ensured that errors when connecting to databases (such as using the Connection String Editor’s test button) don’t expose the connection string which may contain security credentials. #security #integration 21.1.271 #268092
- We’ve added some additional safety checks to ensure you don’t accidentally bulk import the same data twice (causing duplication). #system 21.1.271 #268614
- Resolved issue where the sample connection string for EXECUTE_INTERNAL wasn’t able to be copied into a plugin because of case-senstivity issues. #system 21.1.271 #269490
- The system will now wait for all scheduled tasks to complete before shutting down. #system 21.1.271 #280989
- Resolved an issue where the Integration Agent’s table replicator couldn’t handle null boolean values on SQL Server. #integration agent 21.1.270 #268904
- We’ve eliminated a potential memory leak in Operational Scheduling where the detail grids (below the gantt) weren’t always cleaned up properly when we didn’t need them any more. #performance #opsched 21.1.270 #279943
- Added a rate limiter to the new Duplicate API call checker to avoid overloading logs. #system 21.1.270 #284913